
文章作者:泊东吴
责任编辑:门泊东吴
文章发表于
接之前公众号推送的文章《【优化】交替方向乘子法(ADMM)的基本原理》,本文从所求解的优化问题的形式出发,分成三大类归纳整理ADMM算法的经典使用。
文章作者: @门泊东吴
责任编辑: @门泊东吴
文章发表于微信公众号【运筹OR帷幄】:【优化】交替方向乘子法(ADMM)的基本原理
欢迎原链接转发,转载请私信@运筹OR帷幄获取信息,盗版必究。
敬请关注和扩散本专栏及同名公众号,会邀请全球知名学者发布运筹学、人工智能中优化理论等相关干货、知乎Live及行业动态
更多精彩文章,欢迎访问我们的机构号:@运筹OR帷幄

之前公众号推送了文章《【优化】交替方向乘子法(ADMM)的基本原理》,主要参考的是Stephen Boyd等人写的经典小册子[1],其中的第三章最为相关。我想接着前面讲的流程和原理,整理一下ADMM算法在求解各种优化问题上的经典使用,学艺不精,一知半(不)解,欢迎大家批评指正。
在讲应用之前,我想先聊聊关于N-block ADMM的直接推广。大家都知道,(naive) ADMM works for 2 blocks,很多人也都提到了,从2-block到N-block的直接推广并不trivial,那什么是N-block的直接推广呢?我们不妨来写一下,假设有这样一个线性约束的N-block凸优化问题:



在实际应用中,有很多(大规模)凸优化问题可以写成上述N-block形式,而N-block ADMM的直接推广并不trivial,那为什么ADMM在求解(分布式)凸优化问题上还有那么广泛的应用呢?是如何被使用的呢?我觉得,关键在于问题的巧妙变形。下面,我想尝试从ADMM所求解的优化问题的形式出发,把它的经典使用分成三大类进行归纳整理,希望能帮助大家更好地理解这个算法,内容主要摘自[1]的4-8章还有平时读到的一些paper。

2.1 直接使用

2.2原问题变形后使用



机器学习的标准范式:loss function + regularization([1]第6章)

Distributed Model Fitting([1]第8章)


网络优化问题:点 + 边



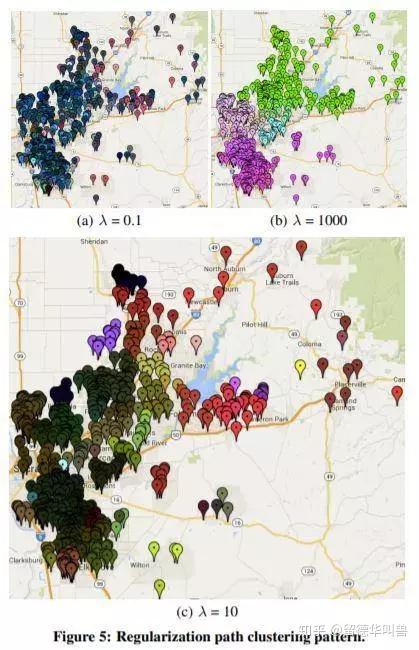

Youth ends when egotism does; maturity begins when one
Basis Pursuit([1]6.2)

Linear/Quadratic Programming([1]5.2)

Consensus Optimization([1]第7章)


其他:Graph Form, Conic Programming,Semidefinite Programming ...
还有一些进阶版的ADMM使用,实在写不动了,就简单提一下吧。基于ADMM的分布式优化算法解graph form of constrained convex optimization:
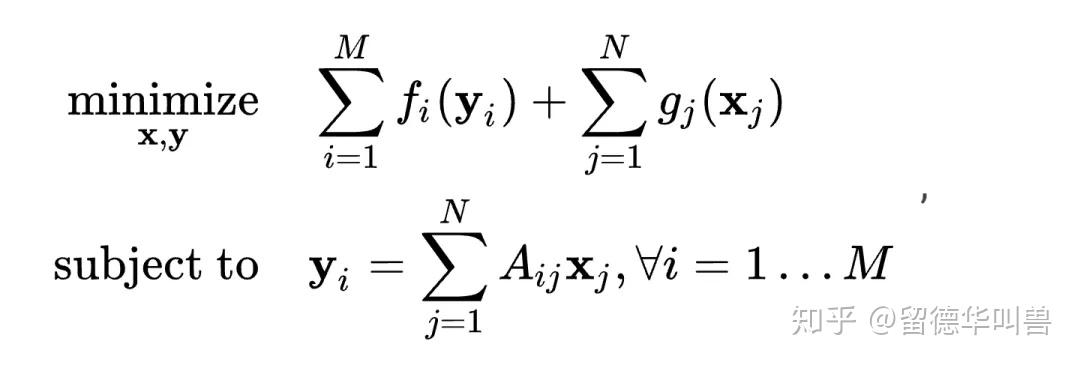
可以参考[8]。用ADMM求解conic optimization可以参考[9],开源代码地址:SCS(https://github.com/cvxgrp/scs)。用ADMM求解semidefinite programming可以参考[10]。
ADMM的直接使用和两类变形使用,都是按我个人的理解划分的,仅供参考,希望以上的归纳整理能帮助大家更好地理解ADMM的工作原理,以后再遇到新的应用,能一眼识破其中玄机。
文章《【优化】交替方向乘子(ADMM)的基本原理》提到了”实际当中你如果写代码跑ADMM会发现它不像那些梯度下降,牛顿法,很容易快速收敛到一个较高的误差精度,ADMM实际的收敛速度往往比那些算法慢得多“,亲手写过代码的人应该都会有同感吧,还有步长的选取,也很tricky,取太小,对约束的满足力度不够,取太大,对目标方程的优化力度又不够;所以实际中,才会考虑取变速率的。插播两个最常用的步长规则(step size rules):
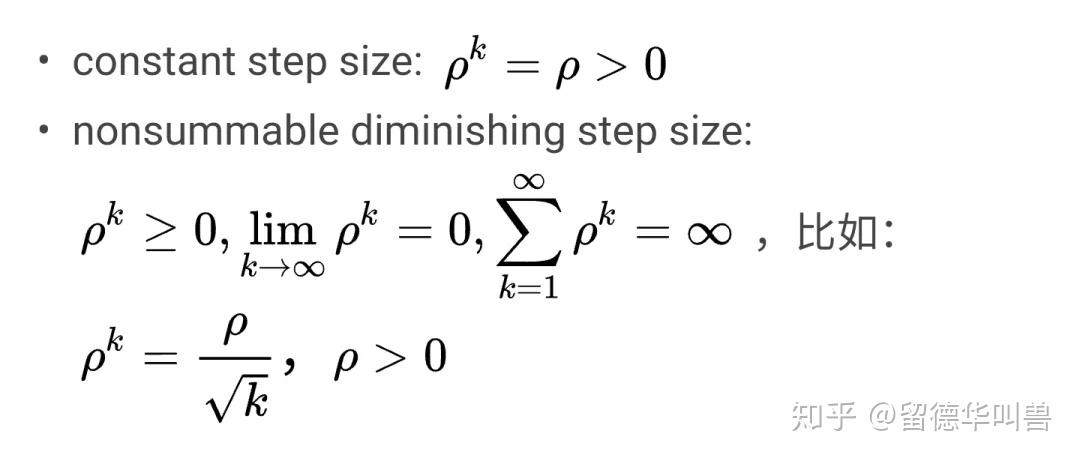
其他步长规则,可以参考[11]的2.2节;这里也给读者留个问题,为什么这么强调 not summable?

为什么ADMM和其他一阶算法在追求高精度解上的收敛表现不佳呢,这就和算法的收敛速率有关了(在物理里面,速率是标量,速度是矢量,所以说速率更好吧),什么是收敛速率?

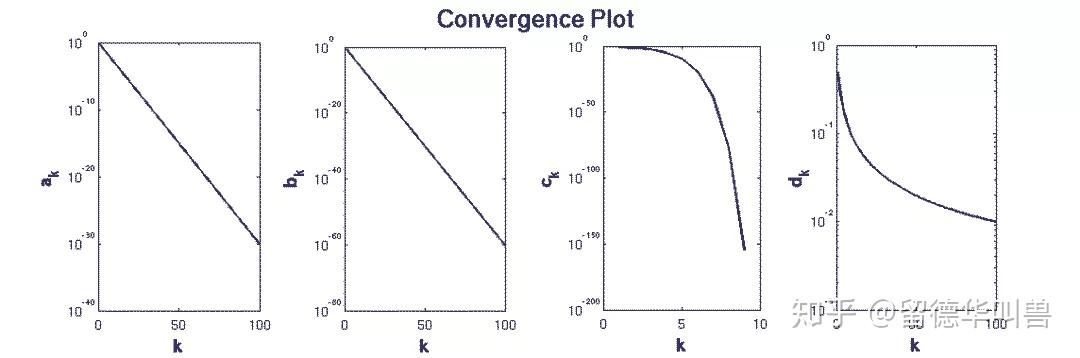

怎么理解这四张图所代表的三种收敛速率呢?一个形象的解释可以是:误差每减小一个数量级(小数点往前移一位,纵坐标往下降一个单位长度)所需要的迭代步数(横坐标往后移的长度),和减少上一个数量级所需要的迭代步数相比,线性、超线性、次线性收敛速率分别对应的是一样、更少、更多,或者类比成匀速运动、加速运动、减速运动。从这个角度理解,通俗地讲,当前迭代所得到的解越接近真实解(从误差数量级衡量),具有线性、超线性、次线性收敛速率的算法分别会趋近得一样快、越来越快、越来越慢。ADMM算法往往能很快收敛到一个低/中精度解,但想进一步提高精度,需要的时间就越来越长了,大家实际编程解大规模问题的时候,最好逐步提高精度。另一个很自然的想法是,在某些使用中,可以把ADMM和一些能从低精度解产生高精度解的算法结合起来使用,参考[12](其实我自己也没仔细看过)。
关于ADMM的研究还在继续,异步、非凸、深度学习...我都没有讲(没啃完),经典应用也一定还有很多我漏掉或者不知道的,欢迎大家讨论补充。写这篇文章的一个初衷,也是为了回答自己内心一直以来的一个疑问,(分布式)优化的算法明明有很多,为什么ADMM能被用得这么广泛?整理完,也很感慨,能对一个算法发掘出这么多花式使用,功劳大概也不输算法的发明者了,嗯,伯乐吧~
参考文献:
[1]S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Eckstein and others, Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers, Foundations and Trends? in Machine Learning, 3(1):1-122, 2011.
[2]C. Chen, B. He, Y. Ye and X. Yuan, The Direct Extension of ADMM for Multi-block Convex Minimization Problems is Not Necessarily Convergent, Mathematical Programming, 155(1-2):57-79, 2016.
[3]H. Wang, A. Banerjee and Z.-Q. Luo, Parallel Direction Method of Multipliers, Advances in Neural Information Processing Systems, pp. 181-189, 2014.
[4]W. Deng, M.-J. Lai, Z. Peng and W. Yin, Parallel Multi-block ADMM with o(1/k) Convergence, Journal of Scientific Computing, 71(2):712-736, 2017.
[5]X. Wang, M. Hong, S. Ma and Z.-Q. Luo, Solving Multiple-block Separable Convex Minimization Problems using Two-block Alternating Direction Method of Multipliers, arXiv preprint arXiv:1308.5294, 2013.
[6]N. Parikh, S. Boyd and others, Proximal Algorithms, Foundations and Trends? in Optimization, 1(3):127-239, 2014.
[7]D. Hallac, J. Leskovec and S. Boyd, Network Lasso: Clustering and Optimization in Large Graphs, Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 387-396, 2015.
[8]N. Parikh, S. Boyd, Block Splitting for Distributed Optimization, Mathematical Programming Computation, 6(1):77-102, 2014.
[9]B. O’Donoghue, E. Chu, N. Parikh and S. Boyd, Conic Optimization via Operator Splitting and Homogeneous Self-dual Embedding, Journal of Optimization Theory and Applications, 169(3):1042-1068, 2016.
[10]Z. Wen, D. Goldfarb and W. Yin, Alternating Direction Augmented Lagrangian Methods for Semidefinite Programming, Mathematical Programming Computation, 2(3-4):203-230, 2010.
[11]S. Boyd and others, Subgradient Methods, Lecture Notes for EE364b(https://web.stanford.edu/class/ee364b/lectures/subgrad_method_notes.pdf), Stanford University, Spring 2013-14.
[12]J. Eckstein and M. C. Ferris, Operator-splitting Methods for Monotone Affine Variational Inequalities, with A Parallel Application to Optimal Control, INFORMS Journal on Computing, 10(2):218-235, 1998.
更多精彩文章欢迎关注我们的机构号@运筹OR帷幄
扫二维码关注『运筹OR帷幄』公众号:

公司名称: 天富娱乐-天富医疗器械销售公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

