

前不久写了LRU算法系列文章,今天来介绍一下和LRU算法并驾齐驱的另一个算法——LFU。
LFU全称是最不经常使用算法(Least Frequently Used),LFU算法的基本思想和所有的缓存算法一样,都是基于locality假设(局部性原理):
如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
LFU是基于这种思想进行设计:一定时期内被访问次数最少的页,在将来被访问到的几率也是最小的。
相比于LRU(Least Recently Use)算法,LFU更加注重于使用的频率。
LFU将数据和数据的访问频次保存在一个容量有限的容器中,当访问一个数据时:
当数据量达到容器的限制后,会剔除掉访问频次最低的数据。下图是一个简易的LFU算法示意图。
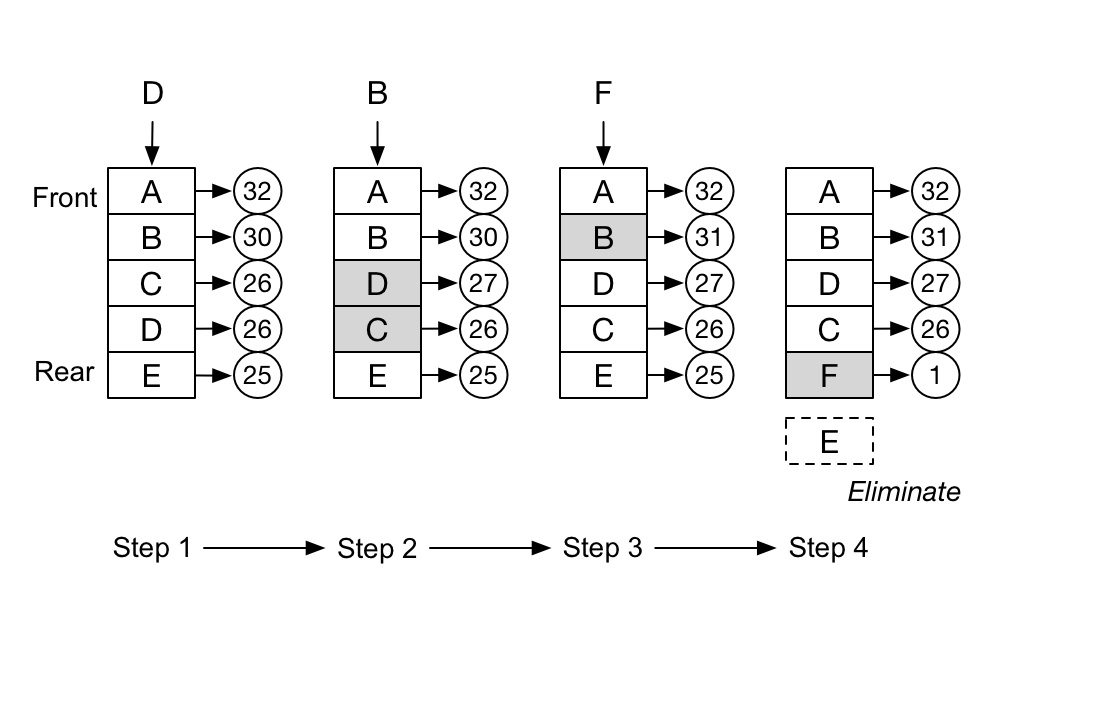
上图中的LRU容器是一个链表,会动态地根据访问频次调整数据在链表中的位置,方便进行数据的淘汰,可以看到,在第四步时,因为需要插入数据F,而淘汰了数据E。
LFU的实现一共有三种方案,但是思想都是一样的,下面我们先来看最简单的一种实现。
整个逻辑还是比较清晰的,注意小心的操纵(前置节点)、(后置节点)这两个指针即可,同时注意通过方法保证链表中的数据是按照访问频次排序的。
也正是因为freqPlus这个方法,导致和操作的时间复杂度都为O(N)。
为了进一步降低上一种方案的时间复杂度,我们可以通过双哈希表来实现。
基于JDK的这个类来模拟链表,我们可以将和操作的时间复杂度降低到O(1)级别。这套方案的实现来自于这篇论文《An O(1) algorithm for implementing the LFU cache eviction scheme》,下面是该论文中的一个示意图,可以辅助理解。
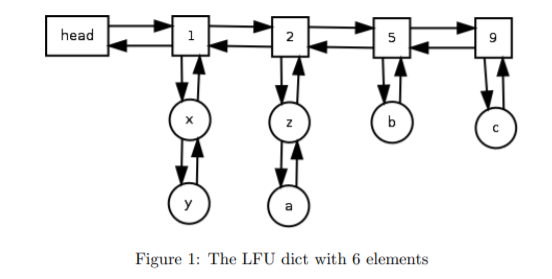
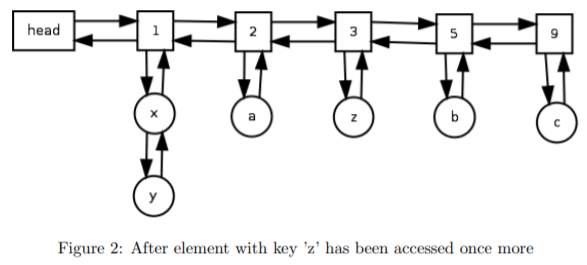
区别:
LFU是基于访问频次的模式,而LRU是基于访问时间的模式。
优势:
在数据访问符合正态分布时,相比于LRU算法,LFU算法的缓存命中率会高一些。
劣势:
从上面的优劣分析中我们可以发现,优化LFU算法可以从下面几点入手:
具体的优化方案我会在之后的文章中结合具体实例进行介绍。
本文介绍了基本的LFU算法,以及它的O(N)级别和O(1)级别的具体实现。后面进行了LRU算法和LFU算法的优劣分析,并得出了LFU算法的优化方向。
公司名称: 天富娱乐-天富医疗器械销售公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

