
学习记录,如有错误请指出,感谢大家指导建议。
Adam是我们现在用的最多的优化器,他是将adaptive 和momentum结合在一起。ada部分参考了RMSProp,momentum就是我们熟知的动量法了。对于RMSProp有疑问的同学可以参考我上一篇的文章。
mt是结合了动量的梯度信息,St和RMSProp中的St定义相同,以指数平滑的方式保留了历史梯度平方信息。Adam会在迭代过程中逐渐将m和S趋于稳定。理解了RMSProp之后,Adam的数学运算过程并不难理解。从个人的经验来看 Adam的训练结果通常较SGD来的更好,因为他对每个参数的学习率更新速度是不同的,而SGD是相同的,所以Adam经过细心调参一般能获得比SGD更好的结果。
接下来结合pytorh代码观察一下Adam。
这是pytorch中Adam的源码参数列表,params是需要训练的参数,beta就是我们的?构成的向量,一般值分别为0.9和0.999。eps为极小值防止分母为0,weight_decay为权重衰减系数,默认为0(目前pytorch中的adam的weight decay实现方式还是有些问题,如要使用weight decay,直接使用adamW)。
amsgrad在这里表示是否启用amsgrad计算方法。在下文ADamW中解释了这一行为。
结合pytrch官方手册关于函数的定义和数学公式
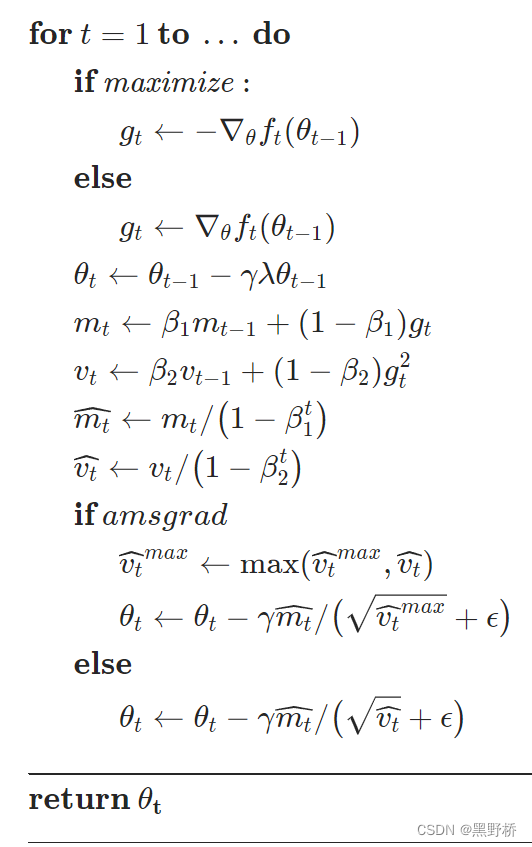
?maximize是一个flag表示优化的方向,其他参数和上面是一致的。AdamW默认带有系数衰减权重,实现的是‘Adam+’的方式,只不过实现的时候和常规机器学习实现方式并不相同。pytorch实现weight decay的方式似乎和常规所想的不太一致?
都9102年了,别再用Adam + L2 regularization了 - 知乎
Adamax是adam的一个延申,可以简单理解为在权重衰减上比Adam更加猛烈
在动量法中,有一个算法名词叫Nesterov。
比Momentum更快:揭开Nesterov Accelerated Gradient的真面目 - 知乎
这个版本的Adam就是将类似这个元素加入了Adam的处理框架中。NAdam的收敛速度更快。
RAdam通过方差自动控制自适应学习率的打开和关闭。RAdam的效果一般来说较Adam要好一些。
Adam系列的优化器,核心都在于通过自适应的方法调节每个参数的学习率达到快速收敛的效果。在较大学习率的情况下,Adam可以达到比SGD要好的效果,但是Adam容易陷入局部最优。这也很容易理解,因为每个参数的学习率都是自适应的,一旦卡在鞍点就没有其他的动力可以把它带出来。
关于Adam的调参经验可以参考以下知乎。
公司名称: 天富娱乐-天富医疗器械销售公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

