
JVM 调优是一个系统而又复杂的过程,但我们知道,在大多数情况下,我们基本不用去调整 JVM 内存分配,因为一些初始化的参数已经可以保证应用服务正常稳定地工作了。
在应用服务的特定场景下,JVM 内存分配不合理带来的性能表现并不会像内存溢出问题这么突出。一般你没有深入到各项性能指标中去,是很难发现其中隐藏的性能损耗
Ab(ApacheBench) 测试工具是 Apache 提供的一款测试工具,具有简单易上手的特点,在测试 Web 服务时非常实用。
ab 一般都是在 Linux 上用。
安装非常简单,只需要在 Linux 系统中输入 yum -y install httpd-tools或(sudo apt-get install apache2-utils)?命令,就可以了。
安装成功后,输入 ab 命令,可以看到以下信息:

?
ab 工具用来测试 post get 接口请求非常便捷,可以通过参数指定请求数、并发数、请求参数等
测试 get 请求接口
ab -c 10 -n 100 http://www.test.api.com/test/login?userName=test&password=test
测试 post 请求接口
ab-c 10-n 100 ?-p 'post.txt' -T 'application/x-www-form-urlencoded' 'http://test.api.com/test/register'
?
post.txt 为存放 post 参数的文档,存储格式如
usernanme=test&password=test&sex=1
参数的含义:
-n:总请求次数(最小默认为 1);
-c:并发次数(最小默认为 1 且不能大于总请求次数,例如:10 个请求,10 个并发,实际就是 1 人请求 1 次);
-p:post 参数文档路径(-p 和 -T 参数要配合使用);
-T:header 头内容类型(此处切记是大写英文字母 T);
输出中,性能指标参考

?
Requests per second:吞吐率,指某个并发用户数下单位时间内处理的请求数;
Time per request:上面的是用户平均请求等待时间,指处理完成所有请求数所花费的时间 /(总请求数 / 并发用户数);
Time per request:下面的是服务器平均请求处理时间,指处理完成所有请求数所花费的时间 / 总请求数;
Percentage of the requests served within a certain time:每秒请求时间分布情况,指在整个请求中,每个请求的时间长度的分布情况,例如有 50% 的请求响应在 8ms 内,66% 的请求响应在 10ms 内,说明有 16% 的请求在 8ms~10ms 之间。
?
一个高并发系统中的抢购接口,高峰时 5W 的并发请求,且每次请求会产生 20KB 对象(包括订单、用户、优惠券等对象数据)。
我们可以通过一个并发创建一个 1MB 对象的接口来模拟万级并发请求产生大量对象的场景,具体代码如下:

?
AB 压测
对应用服务进行压力测试,模拟不同并发用户数下的服务的响应情况:
1、10 个并发用户/10 万请求量(总)
2、100 个并发用户/10 万请求量(总)
3、1000 个并发用户/10 万请求量(总)
ab -c 10 -n 100000 http://127.0.0.1:8080/jvm/heap
ab -c 100 -n 100000 http://127.0.0.1:8080/jvm/heap
ab -c 1000 -n 100000 http://127.0.0.1:8080/jvm/heap
服务器信息
我本机起一台 Linux 虚拟机,分配的内存为 2G,处理器数量为 2 个。具体信息如下图

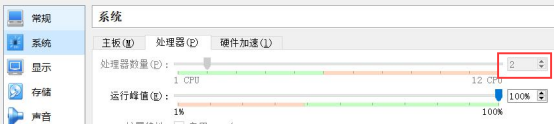

?
GC 监控
还有一句话,无监控不调优,所以我们需要监控起来。JVM 中我们使用 jstat 命令监控一下 JVM 的 GC 情况。
统计 GC 的情况。
jstat-gc 8404 5000 20 | awk '{print $13,$14,$15,$16,$17}只统计我们需要的数据。

堆空间监控
在默认不配置 JVM 堆内存大小的情况下,JVM 根据默认值来配置当前内存大小。
我们可以通过以下命令来查看堆内存配置的默认值:
java -XX:+PrintFlagsFinal -version | grep HeapSize
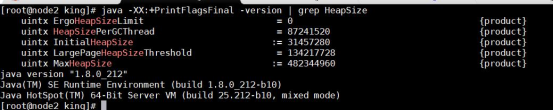
?
测试项目启动
![]()
?
使用 jmap -heap <pid> 这种方式,我们看到这个 JVM 应用占据的堆空间大小
压测结果
10 个并发用户/10 万请求量(总)
使用 AB 进行压力测试:
ab -c 10 -n 100000 http://127.0.0.1:8080/jvm/heap


统计 GC 情况
jstat -gc 9656 5000 20 | awk '{print $13,$14,$15,$16,$17}

测试结果
一起 GC 耗时 17 秒
100?个并发用户/10 万请求量(总)
使用 AB 进行压力测试:
ab -c 100 -n 100000?http://127.0.0.1:8080/jvm/heap

测试结果
?
1000?个并发用户/10 万请求量(总)
使用 AB 进行压力测试:
ab -c 1000 -n 100000 http://127.0.0.1:8080/jvm/heap

测试结果
结果分析
GC 频率
高频的 FullGC 会给系统带来非常大的性能消耗,虽然 MinorGC 相对 FullGC 来说好了许多,但过多的 MinorGC 仍会给系统带来压力。
堆内存大小
堆内存又分为年轻代内存和老年代内存。堆内存不足,会增加 MinorGC ,影响系统性能。
吞吐量
频繁的 GC 将会引起线程的上下文切换,增加系统的性能开销,从而影响每次处理的线程请求,最终导致系统的吞吐量下降。(STW会导致线程挂起,导致该线程让出CPU执行权,其他线程占用CPU继续执行。这个行为就是上下文切换)。
?
延时
JVM 的 GC 持续时间也会影响到每次请求的响应时间。
调优方案
方案一(增大堆内存)
10 个并发用户/10 万请求量(总)
调整堆内存空间,减少GC次数。堆内存基本被用完了。而且存在大量的MinorGC和FullGC,这意味着我们的堆内存严重不足。这时候我们需要调整堆内存的最大空间。
堆内存加大到1.5G
java -jar -Xms1500m -Xmx1500m jvm-1.0-SNAPSHOT.jar
使用 AB 进行压力测试: ?
ab -c 10 -n 100000 http://127.0.0.1:8080/jvm/heap

右。
起 GC 耗时 34 秒
100?个并发用户/10 万请求量(总)
使用 AB 进行压力测试:
ab -c 100 -n 100000 http://127.0.0.1:8080/jvm/heap

1000?个并发用户/10 万请求量(总)
使用 AB 进行压力测试:
ab -c 1000?-n 100000 http://127.0.0.1:8080/jvm/heap

?
?
66 秒 ,还有 8 次 FGC,9 秒左右,加在一起 GC 耗时 75 秒
?
我们可能会惊讶与以上实验。我们经过本次优化,无论是吞吐量,GC时间,都变长了?
这是什么原因呢?保持疑惑继续往下测试。
方案二 (调整新生代大小以及Eden,Servivor区域比例)
堆内存保持不变(1.5个G),Eden区域分配1个G。Eden,Servivor的比例调整位固定1:8。继续进行测试。
10 个并发用户/10 万请求量(总)
java -jar -Xms1500m -Xmx1500m -Xmn1000m -XX:SurvivorRatio=8 jvm-1.0-SNAPSHOT.jar
使用 AB 进行压力测试:
?ab -c 10 -n 100000?http://127.0.0.1:8080/jvm/heap

?
100?个并发用户/10 万请求量(总)
java -jar -Xms1500m -Xmx1500m -Xmn1000m -XX:SurvivorRatio=8 jvm-1.0-SNAPSHOT.jar
使用 AB 进行压力测试:
?ab -c 100?-n 100000?http://127.0.0.1:8080/jvm/heap

耗时 11 秒 ,没有 FGC,加在一起 GC 耗时 11 秒
?
1000?个并发用户/10 万请求量(总)
java -jar -Xms1500m -Xmx1500m -Xmn1000m -XX:SurvivorRatio=8 jvm-1.0-SNAPSHOT.jar
使用 AB 进行压力测试:
?ab -c 1000?-n 100000?http://127.0.0.1:8080/jvm/heap

我们经过第二次调优,性能明显得到了加强。这中间的原理是什么呢?

一般情况下,高并发业务场景中,需要一个比较大的堆空间,而默认参数情况下,堆空间不会很大。所以我们有必要进行调整。
但是不要单纯的调整堆的总大小,要调整新生代和老年代的比例,以及 Eden 区还有 From 区,还有 To 区的比例。
所以在我们上述的测试中,调整方案二,得到结果是最好的。在三种测试情况下都能够有非常好的性能指标,同时 GC 耗时相对控制也较好。
对于调整方案一,就是单纯的加大堆空间,里面的比例不适合高并发场景,反而导致堆空间变大。整个堆扩大了2倍,但是我们的Eden区却之扩大了零点几倍。而我们的新生代垃圾回收主要触发条件就是Eden区域满了。所以此次优化并没有明显减少 GC 的次数,但是每次 GC 需要检索对象的堆空间更大,所以 GC 耗时更长。(此处第一次听到的时候我有一个疑惑,就是Eden区不是没怎么增大么?为啥扫描时间增长了?有这个疑惑的朋友证明知识还没有完全串起来。我们想想我们判断对象是否存活的条件,再想想为什么有跨代引用的问题要解决?没错,就是为了优化我们的扫描标记成本!我们判断垃圾是根据可达性分析算法,所以Eden区域的对象不一定是被新的GCRoots创建的,也可能是我们的Servivor对象,或者老年代的对象创建的。因此,扫描时间与整个堆的大小是挂钩的!)
方案二:调整为一个很大的新生代和一个较小的老年代.原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而老年代尽存放长期存活对象。
由于新生代空间较小,Eden 区很快被填满,就会导致频繁 Minor GC,因此我们可以通过增大新生代空间来降低 Minor GC 的频率。
单次 Minor GC 时间是由两部分组成:T1(扫描新生代)和 T2(复制存活对象)。
默认情况:一个对象在 Eden 区的存活时间为 500ms,Minor GC 的时间间隔是 300ms,因为这个对象存活时间>间隔时间,那么正常情况下,Minor
GC 的时间为 :T1+T2。
方案一:整堆空间加大,但是新生代没有增大多少,对象在 Eden 区的存活时间为 500ms,Minor GC 的时间可能会扩大到 400ms,因为这个对象存
活时间>间隔时间,那么正常情况下,Minor GC 的时间为 :T1*1.5(Eden 区加大了)+T2
方案二:当我们增大新生代空间,Minor GC 的时间间隔可能会扩大到 600ms,此时一个存活 500ms 的对象就会在 Eden 区中被回收掉,此时就不存在复制存活对象了,所以再发生 Minor GC 的时间为:即 T1*2(空间大了)+T2*0
可见,扩容后,Minor GC 时增加了 T1,但省去了 T2 的时间。
在 JVM 中,复制对象的成本要远高于扫描成本。如果在堆内存中存在较多的长期存活的对象,此时增加年轻代空间,反而会增加 Minor GC 的时间。如果堆中的短期对象很多,那么扩容新生代,单次 Minor GC 时间不会显著增加。因此,单次 Minor GC 时间更多取决于 GC 后存活对象的数量,而非 Eden区的大小。
这个就解释了之前的内存调整方案中,方案一为什么性能还差些,但是到了方案二话,性能就有明显的上升
1. 新生代大小选择 ·
2. 老年代大小选择
响应时间优先的应用:老年代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数.如果堆设置小了,可能会造成内存碎 片,高回收频率以及应用暂停而使用传统的标记清除方式;
如果堆大了,则需要较长的收集时间.最优化的方案,一般需要参考以下数据获得:
并发垃圾收集信息、持久代并发收集次数、传统 GC 信息、花在新生代和老年代回收上的时间比例。
吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的新生代和一个较小的老年代.原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,让老年代尽量存放长期存活对象。
?
公司名称: 天富娱乐-天富医疗器械销售公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

