
最优化问题指的是找出实数函数的极大值或极小值,该函数称为目标函数。由于定位\(f(x)\)的极大值与找出\(-f(x)\)的极小值等价,在推导计算方式时仅考虑最小化问题就足够了。极少的优化问题,比如最小二乘法,可以给出封闭的解析解(由正规方程得到)。然而,大多数优化问题,只能给出数值解,需要通过数值迭代算法一步一步地得到。
一些优化问题在要求目标函数最小化的同时还要求满足一些等式或者不等式的约束。比如SVM模型的求解就是有约束优化问题,需要用到非线性规划中的拉格朗日乘子和KKT条件。这里我们仅介绍无约束优化,有约束优化放在后面的章节讲解。
线性函数是指目标函数和约束都为线性的优化问题,非线性规划是指目标函数和约束有一个为非线性的优化问题。线性规划一般在运筹学(经济模型、图论网络流等)中有重要运用,而非线性规划在机器学习中有着重要的运用。我们把主要目光放在非线性规划。
按照斯坦福 Boyd 教授(编写凸优化圣经《convex optimization》的那位)的观点,优化问题的分水岭不是线性和非线性,而是凸和非凸。这句话侧面说明了凸优化做为一种特殊的优化问题,显得非常重要,尤其是在机器学习领域。那么为什么凸优化会如此重要呢?首先我们拉看什么是凸函数。凸函数的定义如下:
① \(Ω\)为凸集,如果对任意的\(x_1,x_2 \in Ω\)以及每一个\(α(0\leqslant \alpha \leqslant 1)\),有 \(f(αx_1+(1-\alpha)x_2)<=αf(x_1) + (1-α)f(x_2)\),则称定义在凸集上的函数\(f\)是凸的(convex)。
② \(Ω\)为凸集,如果对每一个\(α(0<α<1)\)以及\(x_1,x_2 \in Ω\)且\(x_1
eq x_2\),有\(f(αx_1+(1-α)x_2)<αf(x_1) + (1-α)f(x_2)\)则称\(f\)是严格凸的(strictly convex)。
以下展示了几个凸函数的图像例子,从几何角度看没如果图形中两点的连线处处都不在图形的下方,则函数是凸的。或者做为二维空间中的函数,如果函数的图形是碗状的,这个函数就是凸的。
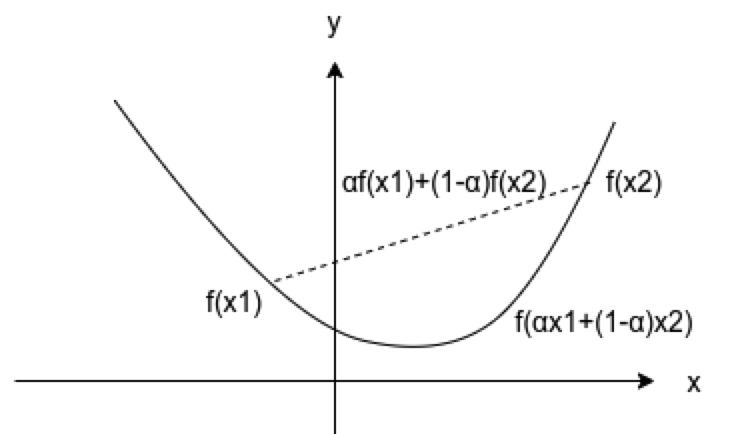
那么凸函数有什么神奇的性质值得我们为之兴奋呢?我们有定理:\(f\)是至少含有一个内点的凸集\(Ω\)上的凸函数,当前仅当\(f\)的Hessian矩阵\(\bm{H}\)在整个\(Ω\)上是半正定的。
此处Hessian矩阵正是函数的曲率概念在\(\R^n\)上的推广,凸函数在每个方向上都有正(至少是非负)的曲率。如果一个函数的Hessian矩阵在一个小区域内是半正定的,则称该函数是局部凸的;如果Hessian矩阵在这个区域内是正定的(但不妨碍我说\(\bm{H}\)在整个\(Ω\)上是半正定的,细品),则称这个函数是严格局部凸的(locally strictly convex)。
以下插入一下函数极值点的必要和充分条件的介绍:
函数极值点的必要和充分条件
而我们对于任意一个无约束优化问题,函数的最值是要满足一阶必要条件和二阶必要条件的。一阶必要条件: 设\(Ω\)是\(\R^n\)的一个子集并且\(f\)是\(Ω\)上的函数。如果\(\bm{x}^*\)是\(f\)在\(Ω\)上的相对极小点,那么对\(\bm{x}^*\)点处的任意一个可行的方向\(\bm{d}∈\R^n\),有\(?f(\bm{x}^*)\bm{d}>=0\)。一个非常重要的特殊情形发生在当\(\bm{x}^*\)在\(Ω\)内部时(\(\bm{x}^*\)是\(Ω\)的内点,\(Ω=\R^n\)就对应这种情形)。在这种情况下,从\(\bm{x^*}\)发散出去的每个方向都是可行方向,因此对所有的\(\bm{d}∈\R^n\),都有\(
abla f(\bm{x}^{*})\bm{d}>=0\),这就意味着\(
abla f(\bm{x}^*)=0\)。二阶必要条件: 设\(Ω\)是\(\R^n\)的一个子集并且\(f\)是\(Ω\)上的函数。如果\(\bm{x}^*\)是\(f\)在\(Ω\)上的相对极小点,那么对\(\bm{x}^*\)处的任意一个可行方向\(\bm{d}∈Ω\),有:
① \(?f(\bm{x}^*)\bm{d}>=0\)
② 如果\(?f(\bm{x}^*)\bm{d}=0\),那么\(d^T?^2f(\bm{x}^*)\bm{d}>=0\)
同样的,我们在无约束情形下,设\(\bm{x}^*\)是集合\(Ω\)的内点。并且设\(\bm{x}^*\)是函数\(f\)在\(Ω\)上的一个内点,那么:
① \(
abla f(\bm{x}^*)=0\)
② 对所有\(\bm{d}\),\(\bm{d}^T?^2f(\bm{x}^*)\bm{d}\geqslant0\)(这个条件等价于说明Hessian矩阵\(\bm{H}\)是半正定的)
二阶充分条件:稍微加强一下二阶必要条件的条件②,我们就能得到\(\bm{x^*}\)是相对极小点的条件:
① \(?f(\bm{x}^*)=0\);
② \(\bm{H}(\bm{x}^*)\)正定。
那么\(\bm{x}^*\)是\(f\)的一个严格相对极小点(因为严格正定,不存在Hessain矩阵\(\bm{H}\)特征值为0的困扰)
而上面说了,如果Hessian矩阵在这个区域内是正定的,则称这个函数是严格局部凸的(locally strictly convex),故我们看出上面说的的二阶充分条件要求在每个点\(\bm{x}^*\)处的函数是严格局部凸的。
推广之,设\(f\)是定义在凸集\(Ω\)上的凸函数,那么使函数达到极小值的点集\(Γ\)是凸集,并且\(f\)的相对极小点也是全局极小点。
这下大家应该知道凸函数的好处了,凸函数没有“坑坑洼洼”,相对极小就是全局极小,这样找到相对极小点就可以收功,便于设计出高效的优化算法,如我们求解SVM中的SMO算法(SVM是个凸优化问题)。而有很多“坑坑洼洼”的函数想要找到全局极小点是NP-hard问题,只能采用遗传算法、退火算法这类启发式算法进行求解。我们在深度学习中的大多数函数(可以把带激活层的神经网络当成一个嵌套的函数)是非凸的,不过我们找到这类函数的全局最小值意义不大,一般我们找到局部极小拟合程度就足够好,从而可以解决我们的问题了。因此,在神经网络中我们一般不采用启发式算法来优化,多是采用随机梯度下降、拟牛顿法、动量法等“更正统”的优化算法来找到局部最优解以近似全局最优解。
在一条已知的直线(只有一个变量)上确定极小点的过程,被称为线搜索(line search)。对于一般不能解析地求极小值的非线性函数,这一过程实际上是采用一些巧妙的沿直线搜索的方法来实现的。这些线搜索技巧实际上就是求解一维极小化问题的方法,因为高维问题最终是通过进行一系列逐次线搜索来求解的,所以这些线搜索方法是非线性规划算法的基石。
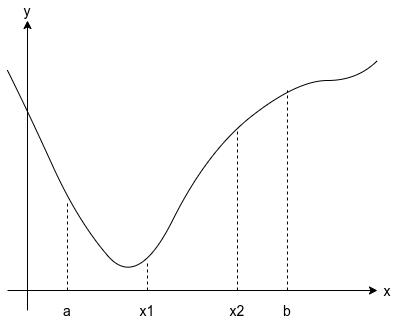
求解线搜索问题的一个最普遍的方法是本节所描述的斐波那契搜索方法。一旦解的范围已知,黄金分割搜索是一种有效找出单变量函数\(f(x)\)的最小值的方式。我们假设\(f\)是一个单峰函数,在区间\([a,b]\)上具有相对极小。选择区间内的两点\(x_1\)和\(x_2\),使得\(a<x_1<x_2<b\)。我们将使用新的更小的区间替换原始区间。根据以下法则该区间可以继续括住极小值。如果\(f(x_1)\leqslant f(x_2)\),则在下一步中保持区间\([a, x_2]\)。如果\(f(x_1)>f(x_2)\),则保持\([x_1, b]\)。如下图所示。
不过,我们如何将\(x_1\)和\(x_2\)放置在区间\([a,b]\)上呢?我们在选择\(x_1\)和\(x2\)时有两个标准:
(a) 关于区间保持对称(由于我们不知道极小在区间的哪一侧)
(b) 选择\(x_1\)和\(x_2\)使得不管在下一步中使用哪种选择,\(x_1\)和\(x_2\)都是下一步中的某个采样点。为了简化讨论,我们以\([a,b]=[0, 1]\)为例子,可以推广到其他区间。即要求\(x_1 = 1 - x_1\)(关于区间中心对称),\(x_1 = x_2^2\)。如下图所示,如果新区间为\([0, x_2]\),标准(b)保证原始的\(x_1\)将会在下个区间中变为\(x_2\),因而仅仅需要进行依次函数求值,即\(f(x_1g)\),(这里\(g\)为\(x_2\)的初始值)同样,如果新的区间为\([x_1, 1]\),则\(x_2\)变为新的"\(x_1\)"。这种重用函数求值的能力意味着在第一步后,每步仅需要目标函数的单次求值。每轮迭代演示如下: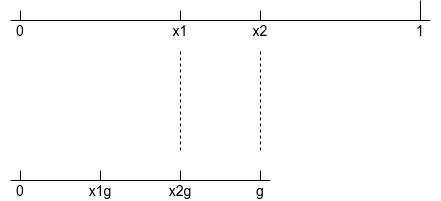
根据上图所示,我们需要选择黄金分割搜索的比例,即\(x_2\)所放置的位置。 旧区间和新区间的比例为\(1/g = (1+ \sqrt{5})/2\),即黄金分割。这样,每轮放置的\(x_1 = 1-g=(1+ \sqrt{5})/2,x_2 = g = ( \sqrt{5} ? 1)/2=0.618\),如下图所示: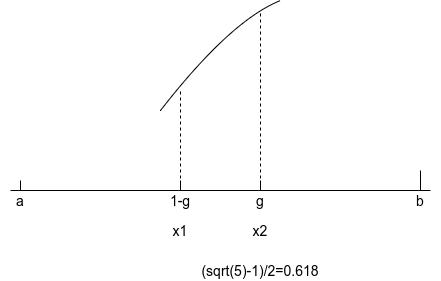
故黄金分割算法如下:
算法的运行结果如下:
可以看到函数\(f(x)=x^6-11x^3+17x^2-7x+1\)在区间\([0,1]\)上的最小值在\(0.2834\)到\(0.2841\)之间,可以近似为\(0.28375\)。
设\(f\)是多元函数,\(\bm{x}^{(t)}\)和\(\bm{x}^{(t+1)}\)都是向量。梯度下降法的迭代式为:
这里\(η\)是优化算法的迭代步长,在机器学习领域一般称为学习率。学习率做为机器学习算法的一个重要的超参数,其大小对机器学习模型的学习效果有着重要影响,太小了迭代算法可能根本无法收敛,太大了可能产生震荡而错过极小值。
梯度下降的算法如下(采用Pytorch框架求梯度):
该算法运行结果如下:
可以看到,算法最终收敛到点\(x^*=( 0.52567, -0.41689)^T\),最小值为\(-0.44577\)。
(注意,这里的求导操作采用的Pytorch内置的Autograd工具,关于Autograd工具的使用,请查阅Pytorch官方文档(地址: https://pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html),这里不再赘述。Pytorch中的Autograd求梯度采用的是反向传播算法(类似与动态规划从后往前逐步计算导数),后面我们在讲解多层感知机的时候会学习这个算法,这里会调用tensor.backward()这个API使用即可。
我们现在有个问题是求函数的。为了找到函数\(f(x)=0\)的根,给定一个初始估计\(x^{(0)}\),画出函数\(f\)在\(x^{(0)}\)点的切线,用切线来近似函数\(f\),求出其与\(x\)轴的交点做为函数\(f\)的根,但是由于函数\(f\)的弯曲,该交点可能并不是精确解,因而,该步骤要迭代进行。
从下面的几何图像中我们可以推出牛顿方法的公式。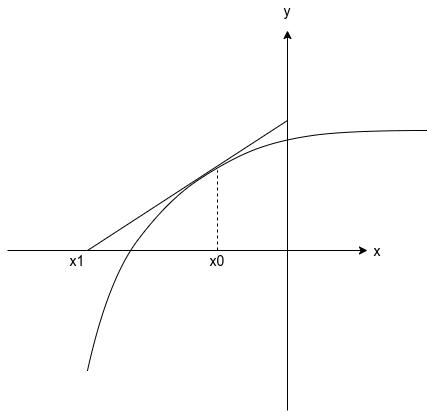 \(x^{(0)}\)点的切线斜率可由导数\(f^{'}(x^{(0)})\)给出,切线上的一点是\((x^{(0)}, f(x^{(0)}))\)。一条直线的点斜率方程是\(y-f(x^{(0)}) = f^{'}(x^{(0)})(x-x^{(0)})\),因而切线和\(x\)轴的交点等价于在直线中令\(y=0\):
\(x^{(0)}\)点的切线斜率可由导数\(f^{'}(x^{(0)})\)给出,切线上的一点是\((x^{(0)}, f(x^{(0)}))\)。一条直线的点斜率方程是\(y-f(x^{(0)}) = f^{'}(x^{(0)})(x-x^{(0)})\),因而切线和\(x\)轴的交点等价于在直线中令\(y=0\):
求解\(x\)得到根的近似,我们称之为\(x^{(1)}\),然后重复整个过程,从\(x^{(1)}\)开始,得到\(x^{(2)}\),等等,进而得到如下的牛顿法迭代公式:
算法实现如下:
该算法运行结果如下:
可以看到,最终方程的根收敛到0.6823278
牛顿法的基本思想是利用一个二次函数局部地近似要极小化的函数\(f\)(对于\(f\)是多元函数的情况,即在某个特定的点用一个曲面去近似函数),然后求出这个近似函数的精确极小点。例如在\(\bm{x}^{(t)}\)附近我们用\(f\)的二阶泰勒展开式来近似\(f\),即:
求上式右端的极小点,即使用上面介绍的牛顿法求解方程\(q^{'}(x)=0\)。
即
这样,我们通过求使得\(q\)的导数为零的点来计算\(f\)极小点\(\bm{x}\)的一个估计值\(\bm{x}^{(t+1)}\)。于是可以得到:
这就是牛顿法的迭代式。如果目标函数单峰,在区间中具有极小值,则使用极小值附近的初始估计开始牛顿方法的计算,这将会收敛到极小值\(\bm{x}^*\)。不过,直接使用矩阵求逆算法复杂度较高(矩阵求逆算法见《Introduction to algorithms》矩阵运算一章), 我们这里采用直接求解方程\(\bm{H}(\bm{x}^{(t)})\bm{v} = -?f(\bm{x}^{(t)})\),并令\(\bm{x}^{(t+1)} = \bm{x}^{(t)} + \bm{v}\), 这样可以提高计算效率(虽然复杂度仍然是\(O(n^3)\),但常数阶减少了)。牛顿法求多元函数极值算法如下:
该算法运行结果如下:
一般而言牛顿法因为利用了二阶导数信息,收敛速度比一阶方法比如梯度下降法要快。
不过牛顿法需要计算Hessian矩阵\(\bm{H}\)的逆,需要\(O(n^3)\)的时间复杂度,\(n\)在这里是变量的维度,在机器学习模型里就是需要优化参数的个数。后来出现了牛顿法的近似版本——拟牛顿法BFGS。
Broyden-Fletcher-Goldfarb-Shanno(BFGS)算法具有牛顿法的一些优点,但没有牛顿法的计算负担。拟牛顿法所采用的方法(BFGS是其中最突出的)是使用矩阵\(\bm{M}^t\)近似逆,迭代地近似更新精度以更好地近似\(\bm{H}^{-1}\)。
BFGS的近似的说明和推导出现在很多关于优化的教科书中,包括Luenberger和叶荫宇编著的《Linear and nonlinear programming》第10章。当Hessian逆近似\(\bm{M}^t\)更新时,变量的最后更新为:
观察公式可知,如果矩阵\(\bm{M}^t\)是\(f\)的Hessian矩阵的逆,这一公式就是牛顿法的迭代公式,如果\(\bm{M}^k= \bm{I}\)(单位矩阵),这一公式对应最速下降法。这里我们选取\(\bm{M}^t\)做为Hessian矩阵逆的近似。不过,即使如此,BFGS算法必须存储Hessian逆矩阵\(\bm{M}^t\),需要\(O(n^2)\)的存储空间,使BFGS不适用于大多数具有百万级参数的现代深度学习模型。
以上我们讨论的连续问题的求解算法,这些问题最大的特点就是我们要优化的变量都是连续型的数值。然而还有一类问题是离散(组合)优化问题,这类问题 要优化的变量常常都是离散的整数,比如最短路径问题、0-1背包问题、旅行商问题(TSP)、哈密顿回路、欧拉回路、网络流问题等,这类问题有些和离散数据结构,比如树、图等有关。这些问题在计算机科学领域有些得到了经典的专用算法,如解决单源最短路径的Dijkstra算法、多源最短路径的Floyd-Warshell算法;解决网络流问题的Ford-Fulkerson算法等,时间复杂度相对较低;但有些问题没有经典的专用算法,需要写成线性规划(常常是整数规划)的形式进行解决,这样算法的时间复杂度往往很高,甚至多项式时间内不可解。
这类问题有些可以在多项式时间内给出解法,如0-1背包问题、欧拉回路问题、网络流问题等,有些在多项式时间内不可解,如旅行商问题(TSP)、哈密顿回路等。(有趣的是,欧拉回路和哈密顿回路极其相似,欧拉回路是使一次性经过所有边的步数最小,哈密顿回路是使一次性经过所有点的步数最小,但欧拉回路在多项式时间内可解,哈密顿回路则不然)我们一般把在多项式时间内无法找到全局最优解的问题称为NP-Hard的。一般神经网络想找到全局最优解就是NP-Hard的,不过我们常常用局部最优解来近似全局最优解,这样就已经能取得不错的拟合效果了。故如何将问题表述成线性规划形式可参见《Introduction to algorithms》第29章;具体的P问题、NP问题、NPC问题(NP完全问题)、NP-Hard问题的关系可参见《Introduction to algorithms》第34章。
Python 的科学计算库 Scipy 封装了包括线性规划在内的很多优化算法。熟练使用Scipy也是机器学习工程师的必备技能之一。除此之外,在数学建模类似的比赛中Numpy+Scipy+Scikit-learn+Matplotlib等的组合也是可以媲美Matlab的一大杀器。文档地址:https://docs.scipy.org/doc/scipy/index.html源码地址:https://github.com/scipy/scipy
你如果想进一步在运筹学领域发展(包括不限于凸优化、组合优化、图论、 动态规划、近似算法等)从事诸如美团物流法研发工程师等岗位,那么你可以进一步接触大规模优化工具,比如CPLEX,Gurobi,Xpress等商业优化求解器(算法包)其实,运筹学和控制论无处不在,强化学习的核心—Bellman-Ford方程就源于最优控制和动态规划。
文档地址:https://www.ibm.com/analytics/cplex-optimizer源码地址:不开源
文档地址:https://www.gurobi.com/源码地址:不开源
文档地址:https://www.fico.com/en/products/fico-xpress-optimization源码地址:不开源
自动求导和计算图是深度学习的精华,它是数学和工程的结合,是一个艺术品,熟练掌握Tensorflow和Pytorch等框架的自动求导机制非常重要,尤其是后面搭建神经网络模型的时候方便debug。后面我们会详细介绍自动求导机制所用到的反向传播算法的底层实现,这里大家可以先通过阅读官方文档和源码的方式熟悉下。(Tensorflow和Pytorch的核心源码都是C++,需要一定的C++甚至 CUDA 的基础(因为涉及到GPU并行加速))
文档地址: https://pytorch.org/源码地址:https://github.com/pytorch/pytorch
文档地址: https://tensorflow.google.cn/源码地址:https://github.com/tensorflow/tensorflow
最后,Pytorch 也好,Tensorflow 也罢,它们所采用的自动求导机制都是数值求导,最终只能求出导数的数值。假如说我想知道一个给定函数的符号求导的导函数解析式呢?或者说我给定一个函数式子,想知道这个式子的不定积分解析式是什么样的呢?(尤其是在完成数学作业的时候,尤其是高数O(∩_∩)O 哈哈~)这个时候就像你郑重推荐Python的符号计算库sympy。这玩意有多厉害大家自己下去研究了,我曾经试过它成功积出了21年大学生数学竞赛最后一道压轴题的一道积分,最后每一项都一模一样。。。阅读它的源码也会让你体会到与数值计算不同的另一个世界——符号计算世界的魅力。
文档地址: https://www.sympy.org/en/index.html源码地址:https://github.com/sympy/sympy
公司名称: 天富娱乐-天富医疗器械销售公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

