
在 StackOverflow 上有一个问题?Should we do learning rate decay for adam optimizer - Stack Overflow,我也想过这个问题,对 Adam 这些自适应学习率的方法,还应不应该进行 learning rate decay?
论文 《DECOUPLED WEIGHT DECAY REGULARIZATION》的 Section 4.1 有提到:
上述论文是建议我们在用 Adam 的同时,也可以用 learning rate decay。
我也简单的做了个实验,在 cifar-10 数据集上训练 LeNet-5 模型,一个采用学习率衰减 tf.keras.callbacks.ReduceLROnPlateau(patience=5),另一个不用。optimizer 为 Adam 并使用默认的参数,η=0.001。结果如下:
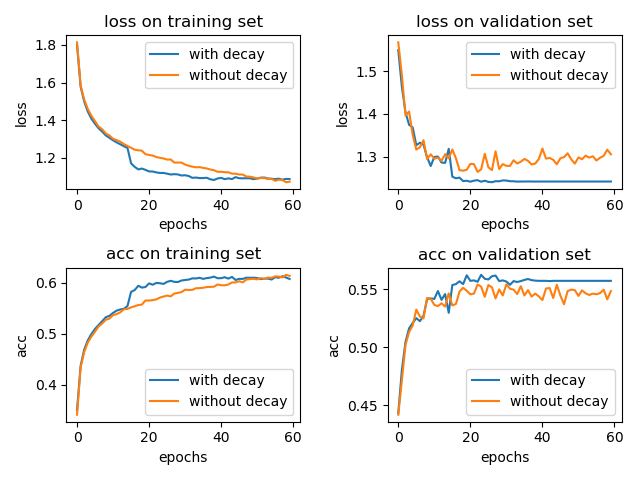
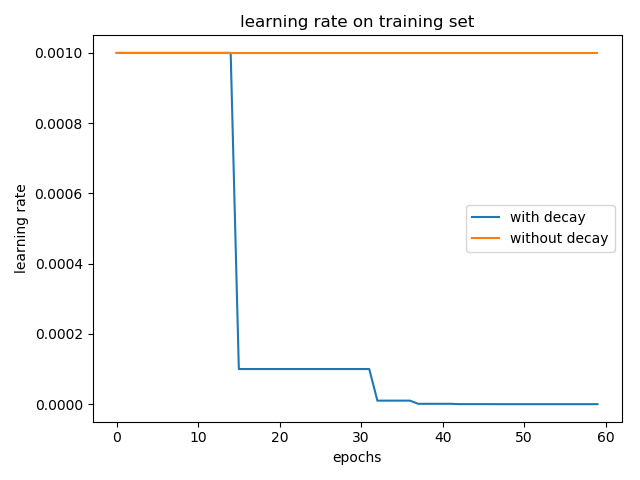
加入学习率衰减和不加两种情况在 test 集合上的 accuracy 分别为: 0.5617 和 0.5476。(实验结果取了两次的平均,实验结果的偶然性还是有的)
通过上面的小实验,我们可以知道,学习率衰减还是有用的。(当然,这里的小实验仅能代表一小部分情况,想要说明学习率衰减百分之百有效果,得有理论上的证明。)
当然,在设置超参数时就可以调低 η 的值,使得不用学习率衰减也可以达到很好的效果,只不过参数更新变慢了。
将学习率从默认的 0.001 改成 0.0001,epoch 增大到 120,实验结果如下所示:
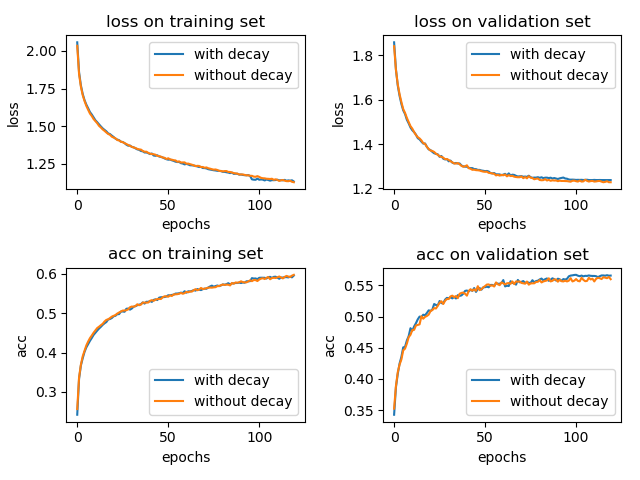
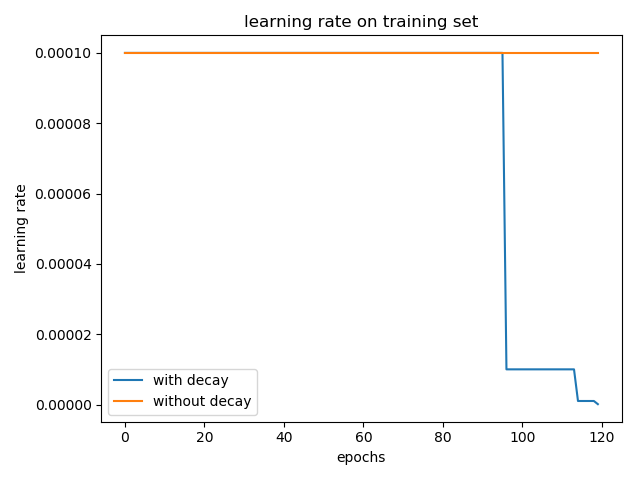
加入学习率衰减和不加两种情况在 test 集合上的 accuracy 分别为: 0.5636 和 0.5688。(三次实验平均,实验结果仍具有偶然性)
这个时候,使用学习率衰减带来的影响可能很小。
那么问题来了,Adam 做不做学习率衰减呢?
我个人会选择做学习率衰减。(仅供参考吧。)在初始学习率设置较大的时候,做学习率衰减比不做要好;而当初始学习率设置就比较小的时候,做学习率衰减似乎有点多余,但从 validation set 上的效果看,做了学习率衰减还是可以有丁点提升的。
ReduceLROnPlateau 在 val_loss 正常下降的时候,对学习率是没有影响的,只有在 patience(默认为 10)个 epoch 内,val_loss 都不下降 1e-4 或者直接上升了,这个时候降低学习率确实是可以很明显提升模型训练效果的,在 val_acc 曲线上看到一个快速上升的过程。对于其它类型的学习率衰减,这里没有过多地介绍。
从上述学习率曲线来看,Adam 做学习率衰减,是对 η 进行,而不是对 ηv^t√+? 进行,但有区别吗?
学习率衰减一般如下:
factor
这些学习率衰减都是直接在原学习率上乘以一个 factor ,对 η 或对 ηv^t√+? 操作,结果都是一样的。
公司名称: 天富娱乐-天富医疗器械销售公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

