
本项目将以对成都市二手房房价的分析与预测为例,完整呈现数据分析中的整个流程,包括数据获取,数据分析和简单的数据挖掘任务。数据将使用Python爬虫从链家网上爬取,然后通过数据分析的方法,对爬取的数据进行分析,并对房价影响因素进行简要分析,在此基础上实现对二手房售价的估计。在此基础上实现对二手房售价的估计。完整项目代码获取请关注微信公众号《做个项目》发送 数据分析 获取。

本文篇幅较长,适合python数据分析初学者进行实践实战。
经过几十年时间的发展,房地产市场发展火热,房价高歌猛进,很多家庭表示为了购买一套房子真的是倾尽了一生的心血。在长期的发展过程中,痛苦的刚需一族迫切地希望房价能够有所降低,但是在很多因素的“助推”下,这么多年房价也没有降下来的势头。房价高位难下,成为了很多家庭的烦恼。房价的分析与预测一直是一个社会热点问题。本章我们将爬取成都链家二手房的房价数据(成都链家二手房网址:https://cd.lianjia.com/ershoufang/),并对二手房房价进行分析和可视化,以及对房价进行简单预测。具体来说,本项目将完成以下任务:
1、 获取成都二手房数据,是从链家网上爬取成都二手房价的相关数据,包括二手房的每平米的售价、总价、地理位置、楼层以及二手房的装修情况等。
2、 针对数据进行分析近年来房屋成交价、房屋面积等进行分析,实现数据可视化。
3、 结合爬取到的数据,判断影响二手房价格的因素,并根据给定的二手房特征对二手房售价进行简单估计。
本小节将针对项目实现的流程及主要原理和方法进行简要分析。
本项目的实现流程如下图所示:
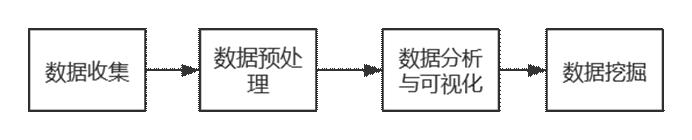
图 1 项目实际过程
从图中我们可以看出,实现本项目的流程包括了数据收集、数据预处理、数据分析与可视化、数据挖掘。
大规模数据的收集主要有两种方法:一种方法是利用API(Application programming interface),API又叫应用程序程序接口,是网站的管理者为了使用者方便,编写的一种程序接口。但是API技术受限于平台开发者。我们通常采用第二种方式,即网络爬虫。网络爬虫是按照一定的规则,自动地爬取网络信息的程序或者脚本。在大数据时代,网络爬虫是从互联网上采集数据的有利工具。
在得到的数据后,就需要对数据进行预处理。数据预处理主要操作为:数据清洗(Data Cleansing);数据转换 (Data Transformation);数据描述( Data Description);特征选择(Feature Selection);特征抽取(Feature Extraction)。数据的预处理对数据分析的准确性有着很大的影响。当数据预处理不当时,这就会使得数据分析的准确性下降。
数据分析与可视化分为两个步骤:数据分析与数据可视化。数据分析是研究大量数据的过程中寻找模式,相关性和其他有用的信息可以帮助帮助我们更好地适应变化,做出明智的决策。数据可视化通俗一点讲,就是将辅助的数据信息,进行图片化展示,目的是为了方便我们从一张杂乱无章的数据里面进行高效的理解和分析,让花费大量时间才能归纳的数据信息,转眼成为一张张看得懂的数据图表。
数据挖掘其实是一种深层次的数据分析方法。数据挖掘可以描述为:按照既定的业务目标,对大量的数据进行探索和分析,揭示隐藏的,未知的或者验证已知的规律性,并进一步将其模型化的先进有效的方法。本章我们将爬取成都链家二手房的房价数据,结合数据预处理的相关操作,对成都二手房房价进行数据可视化,观察数据背后蕴含的信息,最后对成都二手房房价进行相关简单的预测。
? 本项目中需要用到的数据是通过网络爬虫在链家网上获取的,我们将分析从链家网上爬取用于分析的数据的具体思路。
成都链家二手房网页每一页地址如下:
第一页:https://cd.lianjia.com/ershoufang/pg1/
第二页:https://cd.lianjia.com/ershoufang/pg2/
第三页:https://cd.lianjia.com/ershoufang/pg3/
……
我们发现成都链家二手房网页地址可以用下面的公式来表示:https:// + 城市名称拼音缩写 + .lianjia.com/ershoufang/pg +页码+/,根据此规律,就可以获得成都链家二手房的所有网页的网址。例如,获取成都链家二手房网页前3页的url,会得到图 2所示结果:

图 2 前3页url获取结果
获取了url之后,我们需要利用函数requests.get() 来得到该网页下html的内容。但是直接利用requests.get()函数获取html的内容会报错,服务器拒绝访问。大部分网站都有反爬虫的机制,但链家官网的反爬虫机制比较简单,只需要我们添加网页的headers从而模仿人为使用浏览器访问链家二手房网页。打开成都链家二手房官网,键盘按F12,就可以看到图 3所示的开发者工具页面,在开发者工具页面中找到User_Agent,将其中的内容添加到我们所写的爬虫程序中即可。
图 3 开发者工具页面
`添加
headers后,得到
html的内容如下图:```

图 4 html的内容
此时得到的结果并不是我们所想要的内容,肉眼无法获取其中的文字内容,因为这只是简单获取了文本参数,还需要对html的内容进行解析。这个时候,就可以在程序中导入BeautifulSoup,作为我们解析html内容的工具。

图 5 解析html后的内容
在上图中所示的内容包含我们需要的全部内容。但同时我们发现中间掺杂了大量标签, 而我们只需要文字。去除标签则是我们下一步工作,下图就是去标签提取文本内容的结果。

图 6 文本获取结果
我们看到了所需要爬取的内容,只需要把爬取的内容转换成自己想要的格式,然后保存在相关文件中即可。下图是将爬取到的内容保存为CSV文件的示例。

图 7 CSV文件保存
? 获取了数据之后,需要首先对数据进行预处理,本项目中的预处理操作比较简单,直接采用前面章节介绍的相关方法进行即可,本小节我们将讨论针对数据可以进行哪些维度的分析和展示。通过爬取获得的数据包括了二手房的位置,单位平米售价,楼层数,房屋建造时间等数据,通过这些数据我们可以进行相关分析。
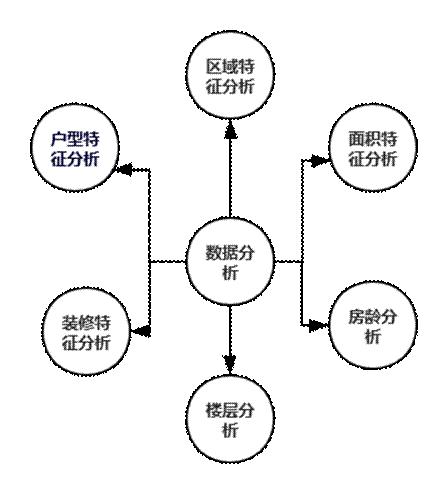
图 8 数据分析
从图中我们可以看出,本项目准备进行的分析包括了户型特征分析、区域特征分析、面积特征分析、装修特征分析、楼层分析和房龄分析,其中:
在完成了基本的数据分析和数据可视化之后,接下来我们将尝试对数据内容进行挖掘,主要包含两部分内容。首先通过热力图,分析房价和哪些因素的关系比较密切,然后再试图利用数据挖掘方法,找出这些因素和房价之间的关系,从而实现利用这些关键因素对房源价格的预测。
在实现热力图绘制是,我们采用了seaborn中的heatmap函数进行绘制,下面的热力图我们展示二手房面积、室厅数、关注人数等因素影响房价的情况。
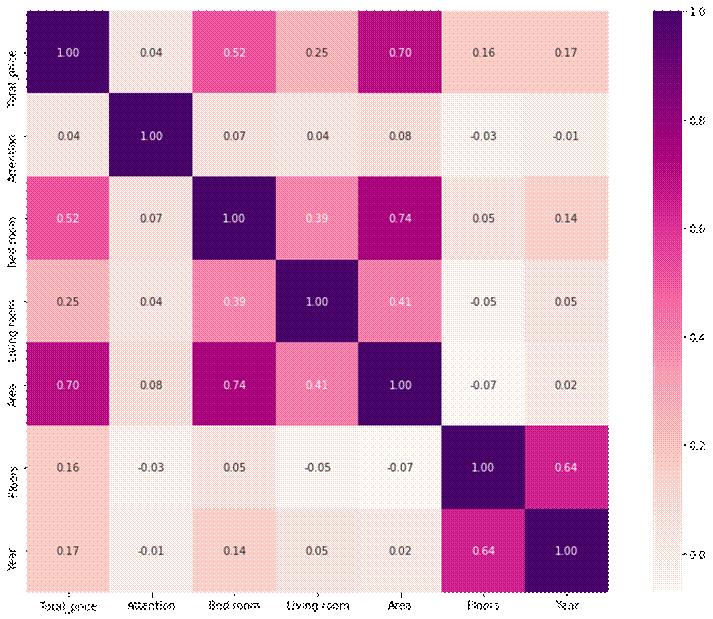
图 9 房价影响因素热力图
图 9中左图中的数字构成了一个对称矩阵。以第二行第一列的0.04为例,这代表关注人数对房价的影响因子为0.04。其中,列表中的数字值越大,代表横纵坐标所代表的两个因素互相影响力越大。矩阵中对角线的数字都为1.00,观察横纵坐标,我们发现其横纵坐标代表的影响是一样的。可以看到,在房价的影响因素里,房屋面积和卧室数是主要的影响因素。
接下来,我们将尝试利用数据挖掘方法,试图找出影响房价的这些因素和房价之间的关系。从热力图分析看出,房屋面积和卧室数是最主要的因素,读者可以只利用这两个因素进行关系挖掘,但此处为了效果更准确,仍然将使用更多的因素进行挖掘。
在预测二手房房价之前,我们与需要对数据进行适当处理。对数据进行One-Hot Encoding处理,是我们的主要操作。One-Hot编码,也称独热编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。由于分类器往往默认数据数据是连续的,并且是有序的,但是在很多机器学习任务中,存在很多离散(分类)特征,因而将特征值转化成数字时,往往也是不连续的, One-Hot 编码解决了这个问题。
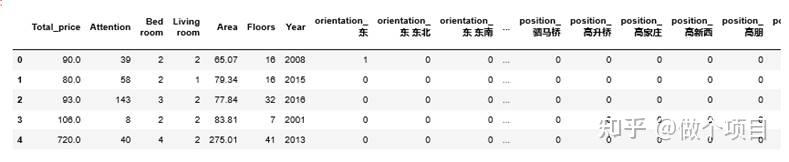
图 10 One-Hot处理结果
如图 10所示,在对数据进行独热编码处理之后,我们发现数据中没有了多余的汉字描述。
在这之后就可以进入模型训练阶段了。此处我们将采用8.3小节介绍的多元线性回归方法建立模型。最终的实现代码和结果将在下一小节详细介绍。
本项目的实现可以直接在Jupyter中编写代码,也可以通过PyCharm将代码分成几个可重用的部分来进行。在代码中,会有相关注释,以便读者理解。
首先需要对数据进行获取,基于上一小节介绍的实现思路,爬取成都链家二手房的数据的详细代码如下:
import re
import requests
from bs4 import BeautifulSoup
def removenone(mylist):#移除参数中空值的函数
while '' in mylist:
mylist.remove('')
return mylist
def addnone(mylist,length,cha):#对文本进行标准化,使其文本格式都一样
while len(mylist) < length:
mylist.append(cha)
return mylist
def regnum(s):#提取爬取到的字符串中的数值
mylist=re.findall(r'[\\d+\\.\\d]*', s)
mylist=removenone(mylist)
return mylist
def lianjia(url,page_range,district):
\\#Initialization
colum_name=['Title','Position','Tag','followInfo','VR','Info','Total_price','RMB/m^2','Attention','Update day','Bed room','Living room','Area','Floors','Year','WebPage']#定义爬取到的文本的表头
data_list=[]#定义一个空的字典,用来储存爬取到的文本
for page in range(page_range):
pgurl=url+'/pg'+str(page+1)
print ("正在爬取的网页地址为:",pgurl)
header={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}
page=requests.get(pgurl, headers=header) #访问网址获取该 html内容
a=page.text
soup=BeautifulSoup(a,"lxml") #解析该html
for b in soup.find_all('div',class_='info clear'): #find_all 找到 div class='info clear' 的标签
temp=[]
for wz in b.find_all('div',class_=['title','positionInfo','tag','houseInfo','priceInfo','followInfo']):
temp.append(wz.get_text())
\\#截取二手房中的房间数,面积,楼层,建造时间
tag=regnum(temp[2])
\\#截取了二手房在链家网上的发布时间以及关注人数
date=regnum(temp[3])
\\#有的二手房发布时间在1年以上,未用数字说明,此处说明其发布时间
date=addnone(date,2,'>365')
\\#截取总价和单价
price=regnum(temp[5])
temp.extend(price)
temp.extend(date)
temp.extend(tag)
\\#将二手房中未给出的数字描述统一赋值为0
temp=addnone(temp,15,'0')
for title in b.find_all('div',class_='title'):
for link in title.find_all('a'):
temp.append(link.get('href'))
data_list.append(temp)
print("爬取完成")
data=pd.DataFrame(data_list,columns=colum_name)#将data转换为dataframe类型
data.to_csv(district+'.csv') #保存数据到CSV文件
return data
if __name__=='__main__':
district_list=[(input('请输入保存文件英文名:'))]#输入
for district in district_list:
url="https://cd.lianjia.com/ershoufang/"
page_range=int(input('请输入爬取页数:')) #输入获得翻页数量
my=lianjia(url,page_range,district)
运行以上代码之后,就可以在创建的后缀为ipynb的程序文件的同目录下,找到一个为你所命名的CSV文件。下面是爬取成都链家二手房前3页的运行结果:

图 11 爬虫运行结果示例
在上面的代码运行成功之后,就可以在创建的后缀为ipynb的程序文件的同目录下,找到一个文件名为cd的XLS文件,如图 12所示:

图 12 csv文件保存
在本章的数据预处理十分简单,此处的预处理包含对数据类型进行转化、清除空值、对异常的数据进行筛选和删除、数据列的拆分(将一列数据拆分为多列数据)等操作,详细数据预处理的实现原理,可参考前面的章节。数据预处理的代码如下:
import pandas as pd#导入pandas库并重新命名为“pd”
file=pd.read_csv('chengdu.csv',encoding='utf-8' )#读取在3.1保存的文件
file=file.drop(['Unnamed: 0','WebPage','Info','VR','followInfo','Title'],axis=1)#删除没有意义的列
print(file.head())
first=file['Tag'].str.split('|',expand=True)#按“|”划分'Tag'列
first.rename(columns={0:'室厅数',1:'面积(平米)',2:'orientation',3:'Style',4:'楼层',5:'建筑时间',6:'Type'},inplace=True)#对新划分的每一列重新命名
df=pd.concat([first, file], axis=1 )#把划分的所有列聚合起来成为一个dataframe
df=df.drop(['室厅数','面积(平米)','楼层','Tag','建筑时间'],axis=1)#删除某些列
\\#df.describe()#可对数据进行描述性分析
df.dropna(axis=0,how='any',inplace=True)
\\#fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)#也可以通过此行代码对空值复制
\\#print(df['Year'].value_counts())#实例代码,读者可自行对其他列进行查看数据是否有异常值
df=df[df['Year']!=0]#删除建筑时间为0的二手房
df=df.reset_index(drop=True)#对每一行的索引重新排序
for i in range (len(df)):#发布时间大于一年的二手房,将>365改为365
if df['Update day'][i]=='>365':
? df['Update day'][i]=str(df['Update day'][i])
? df['Update day'][i]=df['Update day'][i].replace('>365','365')
for i in range (len(df)):
df['Update day'][i]=float(df['Update day'][i])
print("--------")
print(df.head())
运行以上代码,我们可以得到以下结果:
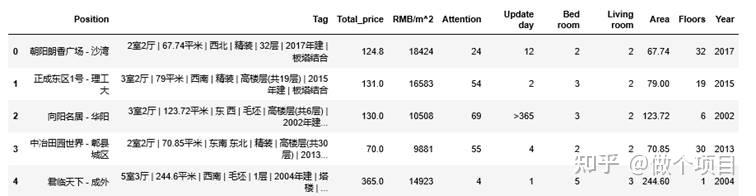
图 13 预处理前的数据

图 14 预处理后的数据
观察图 13和图 14,我们发现处理前后的数据在某些列的名称发生了变化,其中的数据形式也发生了变化,如图 13中的“>365”变成了“365”,图 13中的Tag列中的数据在图 14中变成了多列。
对二手房的数据进行预处理后,数据变得规整,但我们直接观察这些庞大的数据,难以发现其中的规律,于是我们对数据进行相关可视化操作。根据2.3小节的介绍,数据可视化主要实现户型特征可视化、区域特征可视化等,每一个可视化操作的代码如下:
1、户型特征分析:
户型特征主要针对二手房的户型类型数量进行了统计。户型特征分析的代码如下:
import numpy as np#导入numpy
import pandas as pd#导入pandas
import matplotlib.pyplot as plt #导入matplotlib,matploylib为优秀的画图库
import seaborn as sns#导入seaborn,seaborn为优秀的画图库
sns.set(style="darkgrid") #seaborn默认的风格
import matplotlib.pyplot as plt
housetype=df['室厅数'].value_counts()#对户型类型进行统计
from pylab import mpl
mpl.rcParams['font.sans-serif']=['FangSong']# 指定默认字体
mpl.rcParams['axes.unicode_minus']=False # 解决保存图像是负号'-'显示为方块的问题
\\#设置画布
asd,sdf=plt.subplots(1,1,dpi=200)#置图片的相关参数
\\#获取类型数前8条数据
housetype.head(8).plot(kind='pie',x='housetype',y='size',title='户型数量分布')
plt.legend(['数量'])#设置图表
f, ax1=plt.subplots(figsize=(20,20))
sns.countplot(y='室厅数', data=df, ax=ax1)
ax1.set_title('房屋户型',fontsize=15)
ax1.set_xlabel('数量')
ax1.set_ylabel('户型')
plt.show()
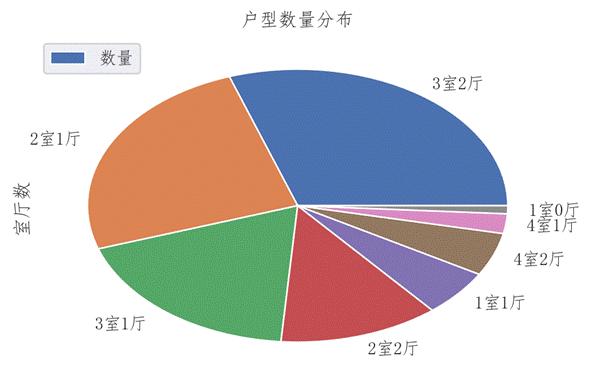
图 15 户型特征数量分布情况
执行上述代码可以得到如图12-15所示的户型分析结果,从图中可以发现,2室1厅的二手房数量和3室2厅的二手房数量差不多,而1室0厅等室厅数的二手房数量很少。1室0厅不能满足一个家庭的生活,2室1厅和3室2厅的户型能够满足大部分人的基本住房需求,更受人们的青睐。
2、区域特征分析
区域特征分析是基于不同小区的二手房数量进行统计及可视化。区域特征分析的代码如下:
xxx=df['Position'].str.split(' -',expand=True)
xxx.rename(columns={0:'position',1:'具体'},inplace=True)
number=xxx['position'].value_counts()
asd,sdf=plt.subplots(1,1,dpi=100)
\\#获取二手房数量最多的前15个小区的数据
number.head(15).plot(kind='bar',x='number',y='size',title='不同地区二手房数量分布',ax=sdf)
plt.legend(['数量'])
plt.show()
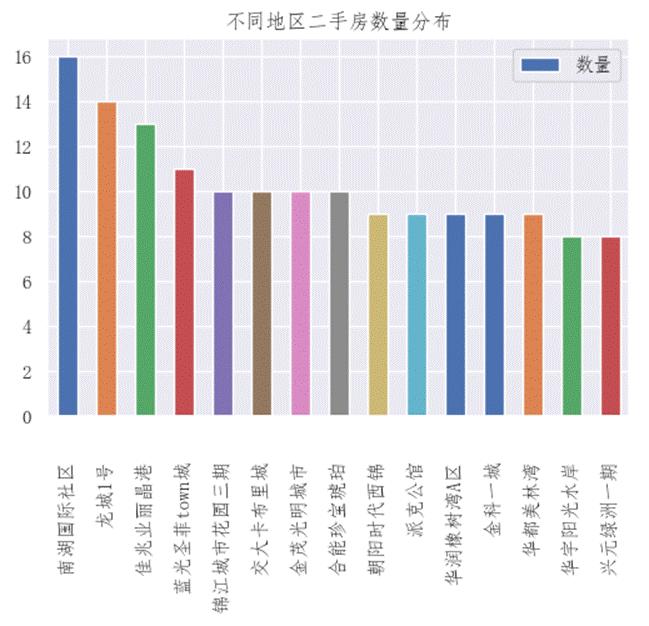
图 16 二手房小区分布情况
执行上述代码可以得到如图12-16所示的分析结果,从图中可以发现,在二手房数量最多的前15个小区中,南湖国际社区就有15套二手房出售。表中的其他小区的二手房数量分布比较均匀,都有9套左右的二手房出售。
3、面积特征分析
二手房的面积是影响房价的一个重要因素,下面的代码对二手房面积划分了区间,且绘制出了二手房面积和二手房售价的线性关系图。
f,ax1=plt.subplots( figsize=(10, 5))
\\#二手房面积的分布情况
sns.distplot(df['Area'], bins=10, ax=ax1, color='r')
f,ax2=plt.subplots( figsize=(10, 8))
\\#二手房面积出售价格的关系
sns.regplot(x='Area', y='Total_price', data=df, ax=ax2)
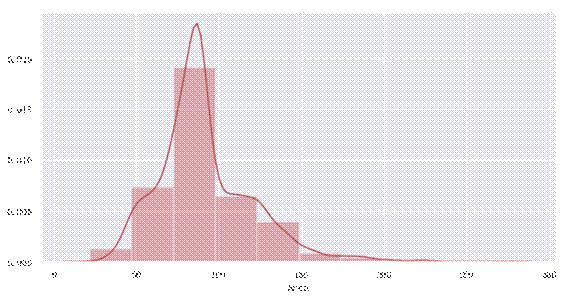
图 17 二手房面积分布情况
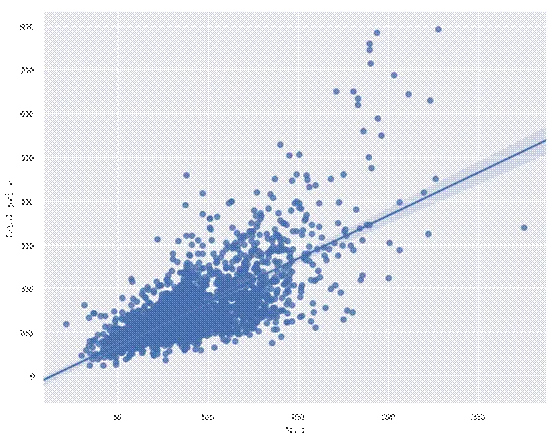
图 18 二手房面积与房价的关系图
执行上述代码可以得到如图12-17和12-18所示的分析结果。图12-17的纵坐标代表二手房数量占比,横坐标代表二手房面积区间。从图中可以发现,在所有的二手房中,面积在90到100平米的二手房数量远远高于其他面积的二手房数量,而面积在300平米以上的二手房的数量几乎为0。通过distplot和kdeplot绘制柱状图观察面积特征的分布情况,属于长尾型分布,这说明了有一些二手房的面积很大,且超出正常范围的二手房。通过regplot绘制了面积和房屋总价之间的散点图,发现面积与总价基本呈现线性关系,符合基本常识:面积越大,价格越高。但是图中也有例外的点:有的二手房面积超过了250平米,价格不到300万元;有的二手房面积在180平米左右,但价格却在800万元左右。
4、装修特征分析
二手房的每平米售价的高低与其装修情况有一定关系,为此,我们将二手房单位售价和其装修情况做了统计分析。下面是装修特征分析的代码:
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'C:\\Windows\\Fonts\\simhei.ttf',size=16)
sns.set(font=myfont.get_name())
sx=sns.lineplot(x=df['Style'], y=df['RMB/m^2'])
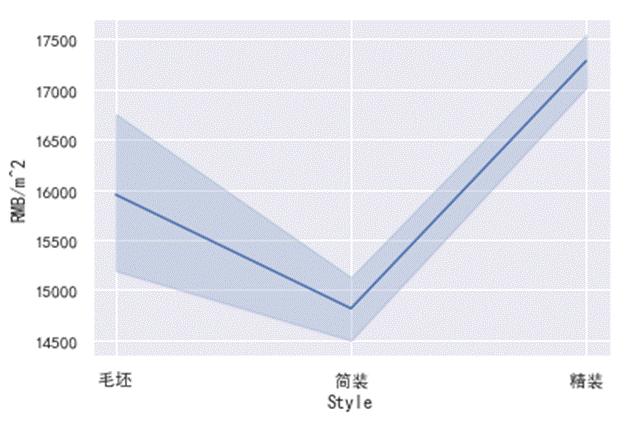
图 19 装修情况与平米售价关系图
执行上述代码可以得到如图12-19所示的分析结果,从图中可以发现,在三种类型的装修情况中,精装二手房的平均每平米售价高于其他三种类型房屋的每平米售价,在精装中每平米售价波动幅度小,其他类型的二手房每平米售价波动十分大。
5、房龄,装修类型及二手房建筑类型综合分析
除了二手房面积会影响房价之外,二手房的其他信息,也会影响房价。因此,我们做相关可视化操作,查看其他因素对房价的影响。房龄,装修类型及二手房建筑类型综合分析的代码如下:
grid=sns.FacetGrid(df, row='Style', col='Type', palette='seismic',size=3)
grid.map(plt.scatter, 'Year', 'RMB/m^2')
grid.add_legend()
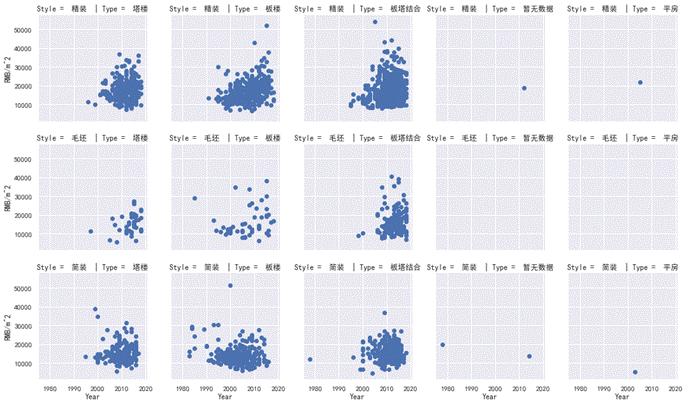
图 20 二手房每平米售价与其他因素的关系图
在上面的20个统计图中,图中每一个小圆点代表一套二手房。第一排的5张统计图中的小圆点为装修风格为“精装”的所有二手房,第二排的5张统计图中的小圆点为装修风格为“毛坯”的所有二手房,第三排的5张统计图中的小圆点为装修风格为“简装”的所有二手房,第四排的5张统计图[g2] 中的小圆点为装修风格为“其他”的所有二手房。第一列的5张统计图中的小圆点为房主建筑类型为“塔类”的所有二手房,其他四列统计图中的小圆点依次代表房屋建筑类型为“板塔结合”,“板楼”,“暂无数据”,“平方”四种类型。在Style(房屋装修风格)和的Type(房屋建筑类型)条件下,使用 FaceGrid 分析二手房建筑时间的特征:整个二手房房价趋势是随着时间增长而增长的,且二手房的建筑年限主要集中的2010年左右。平房以及装修情况未告知的二手房十分少。
6、楼层分析
同户型特征分析一样,我们对不同楼层的二手房进行了统计。楼层分析的代码如下:
f, ax1=plt.subplots(figsize=(20,10))
sns.countplot(x='Floors', data=df, ax=ax1)
ax1.set_title('楼层分析',fontsize=15)
ax1.set_xlabel('楼层数',fontsize=15)
ax1.set_ylabel('数量',fontsize=15)
plt.show()
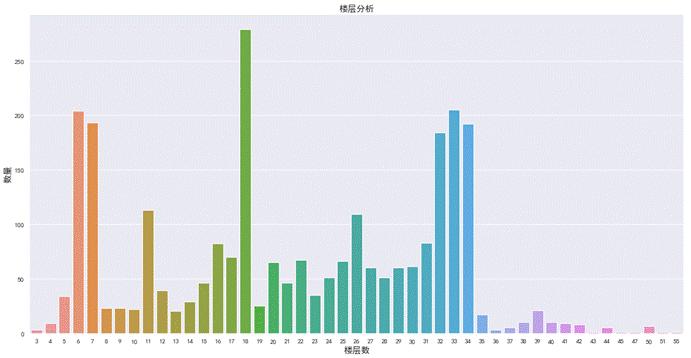
图 21 二手房楼层分析图
执行上述代码可以得到如图12-16所示的分析结果。在中国的传统意识中,认为二手房层数后的数字代表了深远的意义。从图中可以看到,6层、7层、18层和33层二手房数量最多。但是单独的楼层特征没有什么意义,因为每个小区住房的总楼层数都不一样,我们需要知道楼层的相对意义。另外,楼层与文化也有很重要联系,比如中国文化七上八下,七层相对于8层的确是更受欢迎。当然,正常情况下中间楼层是比较受欢迎的,价格也高,底层和顶层受欢迎度较低,价格也相对较低。所以楼层是一个非常复杂的特征,对房价影响也比较大。
在对成都二手房数据进行前面的操作之后,我们期待能通过这些数据,训练出一个模型。此模型能根据二手房的位置、面积等信息,预测二手房目前的售价。详细代码如下:
import pandas as pd#导入pandas库并重新命名为“pd”
import numpy
\\#对每一列重新命名
file=pd.read_csv('chengdu.csv',encoding='utf-8' )
file=file.drop(['Unnamed: 0','WebPage','Info','VR','followInfo','Title'],axis=1)
\\#按“|”划分'面积及楼层'列
first=file['Tag'].str.split('|',expand=True)
\\#对新划分的每一列重新命名
first.rename(columns={0:'室厅数',1:'面积(平米)',2:'orientation',3:'Style',4:'楼层',5:'建筑时间',6:'Type'},inplace=True)
df=pd.concat([first, file], axis=1 )#把划分的所有列聚合起来成为一个dataframe
df=df.drop(['面积(平米)','Tag','建筑时间'],axis=1)
lll=df['楼层'].str.split('(',expand=True)
lll.rename(columns={0:'Layertype',1:'6'},inplace=True)
lll=lll.drop(['6'],axis=1)
df=df.drop(['楼层'],axis=1)
df=pd.concat([df,lll],axis=1)
\\#df.describe()#可对数据进行描述性分析
df.dropna(axis=0,how='any',inplace=True)
\\#fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)#也可以通过此行代码对空值复制
df['Year'].value_counts()#实例代码,读者可自行对其他列进行查看数据是否有异常值
df=df[df['Year']!=0]
df=df[df['RMB/m^2']!=0]
xxx=df['Position'].str.split(' -',expand=True)
xxx.rename(columns={0:'6',1:'position'},inplace=True)
xxx=xxx.drop(['6'],axis=1)
df=df.drop(['Position'],axis=1)
df=pd.concat([df,xxx],axis=1)
df=df .drop(['RMB/m^2','室厅数'],axis=1)
df.reset_index(drop=True, inplace=True)
df.rename(columns={'Update day':'Update_day'},inplace=True)
data=df
import pandas as ppd
df=pd.get_dummies(df)
import seaborn as sns
%pylab inline
pylab.rcParams['figure.figsize']=(15, 10)
corrmatrix1=data.corr()
hm2=sns.heatmap(corrmatrix1,square=True,annot=True,cmap='RdPu',fmt='.2f',annot_kws={'size':10})
from sklearn.model_selection import train_test_split
x=df.drop(['Total_price'],axis=1)
y=df['Total_price']
\\#划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.1, random_state=0)
from sklearn.linear_model import LinearRegression
lr=LinearRegression()
\\# 训练模型
lr.fit(x_train,y_train)
\\# 预测训练集数据
\\#y_train_predict=lr.predict(X_train)
\\# 预测测试集数据
y_test_predict=lr.predict(x_test)
my_submission=pd.DataFrame({'实际价格(万元)': y_test, '预测价格(万元)': y_test_predict })
my_submission.to_csv('test.csv', index=False)
在此处我们将数据划分训练集和测试集,测试集的比重为百分之十。运用多元线性回归(具体原理参见8.3小节相关内容),基于二手房的面积,室厅数,关注人数等因素对房源价格进行估计。
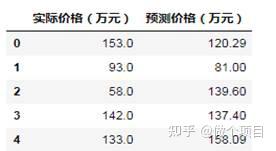
图 22 房价预测结果
我们发现结果并不如意,但当把二手房单位面积的价格也作物预测因素,则实际价格和预测价格会更加接近。当然二手房的价格远不止这些影响因素,读者可以尝试自己改进算法进行挖掘。当然也可以用其他的数据挖掘模型,此处就不再详述,感兴趣的读者可以自己实现。
在房源价格预测的代码中,前半部分为数据预处理的操作。若对数据进行不同的操作,那么就需要对数据进行不同的预处理操作。读者可以发现,在房源价格预测中的预处理与数据预处理小节中的预处理是有差别的。最显著的区别在于房源价格预测中的预处理对数据进行了独热处理。运行房源价格预测中的代码,可以得到2.4 房源价格预测小节中的结果。
当然,此处的代码,是根据二手房的位置、楼层数、二手房关注人数等相关因素,对二手房的现有房价进行预测,若读者有历年来的二手房数据,也可对二手房未来的价格进行预测。
在这个项目中,我们爬取了成都链家二手房网的数据,并对爬取的数据做了相关预处理,得到了完整统一的数据集。在预处理后的数据集的基础上,进行了数据可视化操作。最后,对房屋价进行了影响因素的预测。通过分析,我们发现在成都二手房数据的背后,有着许多规律是二手房数据难以直接体现的,例如在二手房楼层在18层的数量很多,18层在中国人传统思想中意味着不吉利,相比于二手房中厅房数,卧室数更能影响二手房的价格。这也提醒我们,在做数据挖掘时,要多注意数据背后的所蕴含的信息。
公司名称: 天富娱乐-天富医疗器械销售公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

