
同时引入了SGDM的一阶动量和RMSProp二阶动量。
m
t
=
β
1
?
m
t
?
1
+
(
1
?
β
1
)
?
g
t
m_t=β_1*m_{t-1}+(1-β_1)*g_t
mt?=β1??mt?1?+(1?β1?)?gt?
修正一阶动量的偏差: m t ^ = m t 1 ? β 1 t 修正一阶动量的偏差:\widehat{m_t}=\frac{m_t}{1-β^t_1} 修正一阶动量的偏差:mt? ?=1?β1t?mt??
V t = β 2 ? V s t e p ? 1 + ( 1 ? β 2 ) ? g t 2 V_t=β_2*V_{step-1}+(1-β_2)*g^2_t Vt?=β2??Vstep?1?+(1?β2?)?gt2?
修正二阶动量的偏差: V t ^ = m t 1 ? β 2 t 修正二阶动量的偏差:\widehat{V_t}=\frac{m_t}{1-β^t_2} 修正二阶动量的偏差:Vt? ?=1?β2t?mt??
η t = l r ? m t ^ V t ^ = l r ? m t 1 ? β 1 t / V t 1 ? β 2 t η_t=lr*\frac{\widehat{m_t}}{\sqrt{\widehat{V_t}}}=lr*\frac{m_t}{1-β^t_1}/\sqrt{\frac{V_t}{1-β^t_2}} ηt?=lr?Vt? ??mt? ??=lr?1?β1t?mt??/1?β2t?Vt???
参数更新公式: w t + 1 = w t + η t = w t ? l r ? m t 1 ? β 1 t / V t 1 ? β 2 t 参数更新公式:w_{t+1}=w_t+η_t=w_t-lr*\frac{m_t}{1-β^t_1}/\sqrt{\frac{V_t}{1-β^t_2}} 参数更新公式:wt+1?=wt?+ηt?=wt??lr?1?β1t?mt??/1?β2t?Vt???

ADAM:自适应距估计

两位作者分别来自OpenAi和Toronto University。

?摘要主要介绍了Adam算法的一些优点,具体来说就是执行起来很容易、计算非常高效、需要的内存很少而且对于梯度对角缩放具备不变性,非常适合解决大规模数据和参数优化的问题,另外也适于非平稳和非凸优化的这种问题,解决起来即使是很高噪声或者是稀疏梯度的问题,也有很好的效果,另外还有一个特点就是它的超参数可以很直观的解释,并且基本上只需要非常少量的调参。
?后面给出了理论的收敛性的一些验证啊,还有实验结果。

?正文第一段是背景介绍,基于随机梯度的优化在许多科学和工程领域都具有核心的实用性,那许多问题都可以看作是一些标量参数目标函数的优化,也就是求最大化或者最小化的问题,我们知道这个问题说起来很容易,让计算机实验起来会遇到许多困难,比如局部最小值,高原、鞍点、平坦区域、悬崖会产生梯度消失与梯度爆照的问题,另外还有初始点选择错误导致的难以优化等等,所以梯度下降问题依然非常值得研究,但这里作者提到了 ,也就是标准的随机梯度下降算法,他已经证明了SGD非常高效而且有效的优化方法,本文的主要目的是介绍了一种高维参数空间的随机目标优化问题,在这种情况下,高阶的优化方法不太合适了,因为太复杂了,这里仅仅使用了一阶的方法。

?第二段他说我们提出了Adam算法,这是一种有效的随机优化方法,只需要一阶梯度,而且内存的需求量非常小,具体来说呢,该方法跟据梯度的一阶矩阵和二阶矩阵来估计计算不同参数的个体自适应学习率。Adam这个名字是来源于adaptive moment estimation(自适应矩估计),它其实是把两种很流行的算法一个AdaGrad、一个是RMSProp这两种算法结合到了一起。

参数解读:
g
t
?
g
t
:
两个向量逐个元素的乘积
t
:
步数
α
:学习率
θ
:参数
f
(
θ
)
:
目标函数
,
也就是损失函数
g
t
:
梯度,对目标函数求导
?
f
?
θ
β
1
:一阶矩衰减系数
(
指数衰减系数
)
β
2
:二阶矩指数衰减系数
m
t
:
一阶矩
(
g
t
的均值
)
v
t
:
二阶矩
(
g
t
的方差
)
m
t
^
:
m
t
偏执矫正
v
t
^
:
v
t
的偏执矫正
{gt}\bigodot{gt}:两个向量逐个元素的乘积\ :步数\\α:学习率\\θ:参数\\f(θ):目标函数,也就是损失函数\\g_t:梯度,对目标函数求导\frac{\partial f}{\partial θ}\\β1:一阶矩衰减系数(指数衰减系数)\\β2:二阶矩指数衰减系数\\m_t:一阶矩(g_t的均值)\\v_t:二阶矩(g_t的方差)\\\widehat{m_t}:m_t偏执矫正\\\widehat{v_t}:v_t的偏执矫正
gt?gt:两个向量逐个元素的乘积t:步数α:学习率θ:参数f(θ):目标函数,也就是损失函数gt?:梯度,对目标函数求导?θ?f?β1:一阶矩衰减系数(指数衰减系数)β2:二阶矩指数衰减系数mt?:一阶矩(gt?的均值)vt?:二阶矩(gt?的方差)mt?
?:mt?偏执矫正vt?
?:vt?的偏执矫正
算法解析:
t
←
t
+
1
:
更新步数
g
t
←
?
θ
f
t
(
θ
t
?
1
)
:
求梯度
m
t
←
β
1
?
m
?
1
+
(
1
?
β
1
)
?
g
t
:
求一阶矩,也就是过往梯度与当前梯度的均值
,
m
t
?
1
是前一步的均值,
g
t
是当前的梯度
物理意义上是计算一阶动量,类似平滑,通过保持这个匀速直线运动方向上的惯性,来使得一阶矩的更新
v
t
←
β
2
?
v
t
?
1
+
(
1
?
β
2
)
?
g
t
2
:求二阶矩,也就是过往梯度的平滑与当前梯度平方的均值,也就是转动惯量的持续平滑
m
t
^
←
m
t
1
?
β
1
t
v
t
^
←
v
t
1
?
β
2
t
对
m
t
和
v
t
的一个矫正,随时间的增大分数值越来越小,相当于学习率,学习的步长越来越小
θ
t
←
θ
t
?
1
?
α
?
m
t
^
v
t
^
+
?
:
更新参数
θ
,
?
是为了防止分母为
0
,
t\leftarrow{t+1}:更新步数\\ g_t\leftarrow{?_θf_t(θ_{t-1})}:求梯度\\ m_t\leftarrow{β_1*m-1+(1-β_1)*g_t}:求一阶矩,也就是过往梯度与当前梯度的均值,m_{t-1}是前一步的均值,g_t是当前的梯度\\ 物理意义上是计算一阶动量,类似平滑,通过保持这个匀速直线运动方向上的惯性,来使得一阶矩的更新\\ v_t\leftarrowβ_2*v_{t-1}+(1-β_2)*g_t^2:求二阶矩,也就是过往梯度的平滑与当前梯度平方的均值,也就是转动惯量的持续平滑\\\widehat{m_t}\leftarrow{\frac{m_t}{1-β_1^t}} \\\widehat{v_t}\leftarrow{\frac{v_t}{1-β_2^t}}\\ 对m_t和v_t的一个矫正,随时间的增大分数值越来越小,相当于学习率,学习的步长越来越小\\ θ_t\leftarrowθ_{t-1}-{\frac{α*\widehat{m_t}}{\sqrt{\widehat{v_t}}+?}}:更新参数θ,?是为了防止分母为0,
t←t+1:更新步数gt?←?θ?ft?(θt?1?):求梯度mt?←β1??m?1+(1?β1?)?gt?:求一阶矩,也就是过往梯度与当前梯度的均值,mt?1?是前一步的均值,gt?是当前的梯度物理意义上是计算一阶动量,类似平滑,通过保持这个匀速直线运动方向上的惯性,来使得一阶矩的更新vt?←β2??vt?1?+(1?β2?)?gt2?:求二阶矩,也就是过往梯度的平滑与当前梯度平方的均值,也就是转动惯量的持续平滑mt?
?←1?β1t?mt??vt?
?←1?β2t?vt??对mt?和vt?的一个矫正,随时间的增大分数值越来越小,相当于学习率,学习的步长越来越小θt?←θt?1??vt?
??+?α?mt?
??:更新参数θ,?是为了防止分母为0,
?更新参数θ的过程,就好比在崎岖不平的山路上开越野车,那么一阶矩就是控制的方向盘往前开,实现动量的平滑,因为动量就是衡量物体在一个直线运动方向上保持运动的趋势, 二阶矩就是控制左右旋转方向,或者说利用惯性让车往左右转的时候更加平滑,也就是在利用旋转惯性。
?指数衰减的这个β1、β2这两个系数的作用是让它开始的时候调整的快,那快到目的地的时候,逐步的越来越慢。

?最后一段,他说可以通过改变计算顺序来提高算法1的效率,具体的来说就是将循环中的最后三行,替换成最后一行的式子。
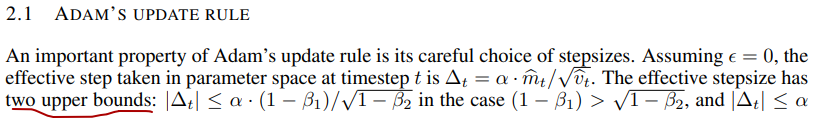
?2.1这一段算是对伪代码规则的一个诠释,他说Adam的一个重要特性就是对步长的谨慎的选择,首先强调了步长的有界性(两个upper bounds)。

?其次,强调在当前参数值下确定了一个置信域要优于没有提供足够信息的当前梯度估计,这正可以令其相对简单的提前知道alpha的一个正确范围,第三,他在这里提出了这样一个信噪比(SNR),说其大小决定了符合真实梯度方向的不确定性,SNR值在最优解的附近趋向于0,因此也会在参数空间有更小的有效步长,从而实现自动退火。
?当Adam算法遇到鞍点的时候,随机梯度下降在鞍点附近移动产生的噪声能让当前点迅速跳出这个鞍点,另外面对一段时间梯度连续为0的平坦区域,或者说梯度稀疏的情况,Adam算法也能利用历史积累的梯度信息快速的穿过,此外当接近极小值的时候,所有方向上的噪声都会很大,从而使得信噪比接近于0,让更新步长迅速减小到0,作者将之为自动退火也就是这个意思了。
?在这一段的最后作者也强调了,Adam算法它对梯度的对角缩放具备不变性,有效步长Δt对于梯度缩放来说仍然是个不变的量。

?接下来的第三部分,是对积累梯度和梯度平方v进行了归一化修正的一种具体理论解释,概括的来说就是,
通过
i
n
i
t
i
a
l
i
z
a
t
i
o
n
b
i
a
s
c
o
r
r
e
c
t
i
o
n
归一化的修正可以将
m
t
和
v
t
这一阶矩、二阶矩放大,使得
t
很小的时候
m
t
^
和
v
t
^
跟
t
很大时的梯度
经过从分的累积之后的
m
t
^
和
v
t
^
的大小能够在同一水平
通过initialization bias correction归一化的修正可以将m_t和v_t这一阶矩、二阶矩放大,使得t很小的时候\hat{m_t}和\hat{v_t}跟t很大时的梯度\\ 经过从分的累积之后的\hat{m_t}和\hat{v_t}的大小能够在同一水平
通过initializationbiascorrection归一化的修正可以将mt?和vt?这一阶矩、二阶矩放大,使得t很小的时候mt?^?和vt?^?跟t很大时的梯度经过从分的累积之后的mt?^?和vt?^?的大小能够在同一水平
?具体的来说公式1是一个指数加权平均数的完全展开式,公式2就是为了让指数指数加权平均数v_t和真实值g_t平方更加接近,求期望,看两者之间的差别。在下面指出了指数加权平均数的偏差修正公式的由来。

第四部分主要用在线学习框架分析了Adam算法的收敛性。

?第五部分主要讲了和其它文献其它算法的相关性,梯度下降算法经历了一个发展的历程,首先是从SGD随机梯度下降算法开始,然后发展出了RMSProp、AdaGrad还有改进的AdaDelta等等,这样的很多种的梯度下降算法,本文重点比较了AdaGrad和RMSProp这两种算法,因为是在这两个算法的基础上发展出来的Adam算法,把他们两者的优点结合到了一起,作者为了区分具体的分析了Adam和这两种算法的不同。

?先来看看AdaGrad(自适应梯度算法),它是让不同的参数有不同的学习率,增加了衰减项,提供了稀疏梯度问题的性能,比方说在NLP和视觉领域里边,大量的问题都是梯度都是稀疏梯度的这种情况,对于RMSProp,实际上是均方根传播,它也是维护了每个参数的学习率,但根据最近的权重梯度平均值来调整。
?Adam算法把两者的优点结合到了一起,不同的参数有自己的学习率,而且还有自己的动量,也就是说更加的个性化,因此每个参数更加独立,提升了模型的训练速度和稳定性。
?从区别上来讲,RMSProp算法和Adam算法相比,它在带动量计算时重新计算梯度上的动量,而不是指数加权平均数的算法,没有偏差修正,AdaGrad算法与Adam算法相比,前者参数更新是没有β的,有偏差修正。

?第六部分是实验结果,从report的数据来看,作者分别用逻辑回归加上MNIST、多层神经网络加上MNIST、卷积神经网络加上CIFAR10进行了实验,将Adam算法与其它优化算法进行了详细的对比,实验的细节写的非常清楚。
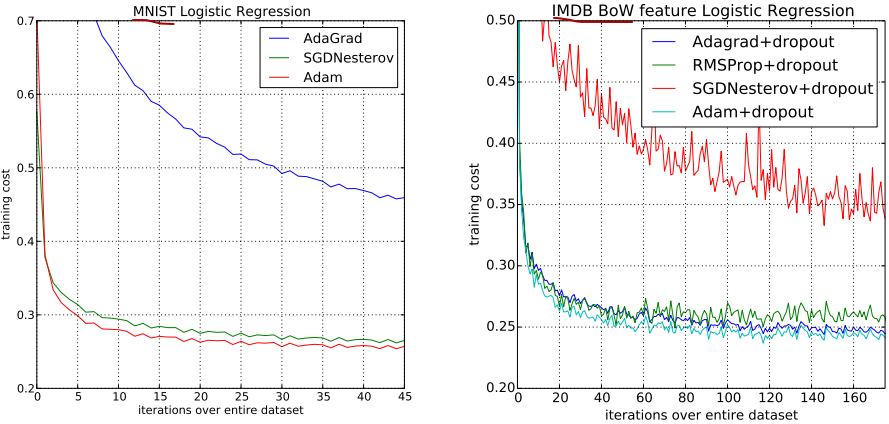

?先看逻辑回归的这个图,逻辑回归是标准的凸函数,因此在优化时不需要担心局部最优解的问题,第一个对比是在MNIST上计算时采用了一个衰减,我们可以看到Adam在收敛域上和SGDN算法这两条线比较接近,快于AdaGrad。
?第二组对比是在IMDB movie review这个数据集上,由于数据本身就是特别稀疏的,可以看到SGDN的表现不是很好,相对于Adam来说,无论是Adam还是RMSProp还是AdaGrad,他们都比这个SGDN强不少。
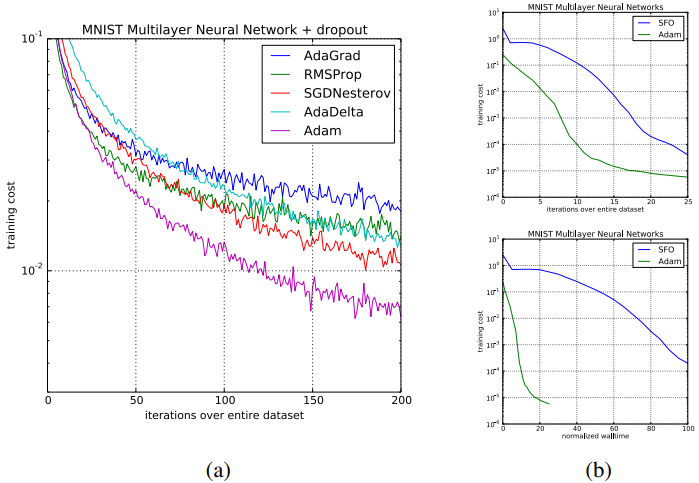

?再来看一下图二,这个是对常用的多层神经网络的一个实验,由于通常这种网络用来拟合非凸函数,因此可以测试Adam优化器不受局部最优解限制的能力,实验结果上来看,在MNIST images上,Adam在收敛速率以及最小化损失函数上,都比其它的优化器要出色不少。
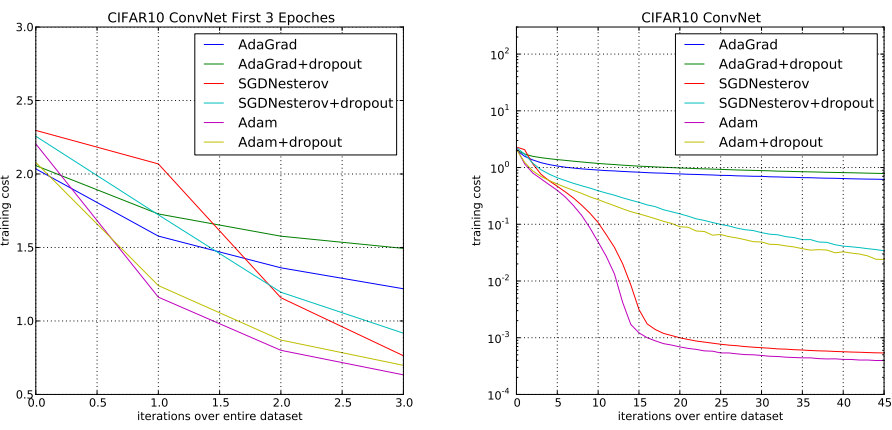
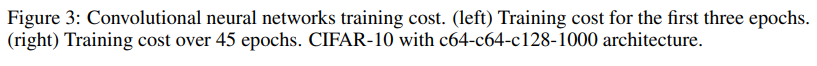
?接下来的测试都是更加复杂的卷积神经网络,来看图三,这个主要是来测试Adam是否能够针对不同的model都取得不错的优化结果,这次是在CIFAR10数据集上,Adam任然取得了最好的一个结果。
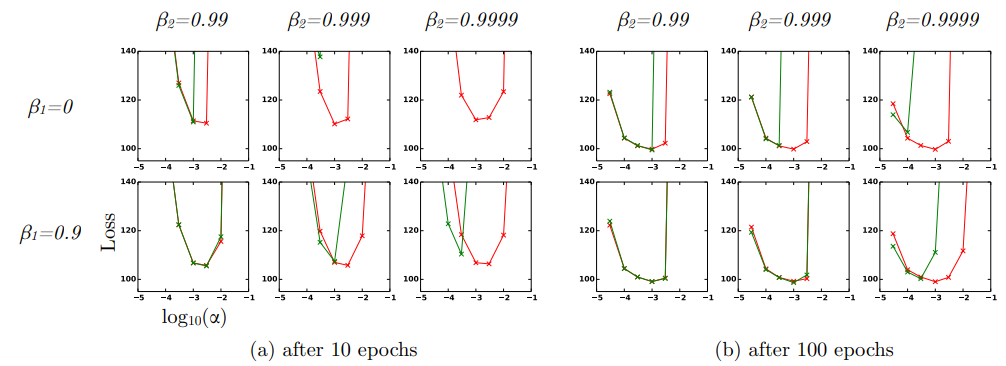

?图四测试了偏差矫正项对于结果的影响,图中绿线为移除bias term的结果,红线为保留bias term偏差项的结果,由于移除bias term之后,Adam的算法也是比较接近于RMSProp,因此可以得出Adam的优化能力不弱于RMPSrop,具体执行的是2013年的这篇paper里面的VAE模型

?第七部分主要讲解了,Adam的一个变体Adamax,也是很多数学的分析。和Adam相比,唯一变动的就是红圈的地方,mt有偏差修正,反倒是vt不见了,改成了ut。

?除了简单的总结之外,作者还提出了下一步研究的方向主要是Adam超参数的设置,同时也指出了一些缺点的改进,Adam虽然收敛的很快很稳定,但是收敛的时候是有些差的,即收敛到它的最优解的准确率要偏低一点,因此也有一些更好的优化算法后来对Adam进行一些改进。
公司名称: 天富娱乐-天富医疗器械销售公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

