
本文是利用pytorch自定义CNN网络系列的第四篇,主要介绍如何训练一个CNN网络,关于本系列的全文见这里。
笔者的运行环境:CPU (AMD Ryzen? 5 4600U) + pytorch (1.13,CPU版) + jupyter;
训练模型是为了得到合适的参数权重,设计模型的训练时,最重要的就是损失函数和优化器的选择。损失函数(Loss function)是用于衡量模型所作出的预测离真实值(Ground Truth)之间的偏离程度,损失函数值越小,模型的鲁棒性越好。当损失函数值过大时,我们就需要借助优化器(Optimizer)对模型参数进行更新,使预测值和真实值的偏离程度减小。
在机器学习中,损失函数(Loss function)是代价函数(Cost function)的一部分,而代价函数则是目标函数(Objective function)的一种类型。它们的定义如下,
损失函数(Loss function):用于定义单个训练样本与真实值之间的误差;
代价函数(Cost function):用于定义单个批次/整个训练集样本与真实值之间的误差;
目标函数(Objective function):泛指任意可以被优化的函数。
损失函数是用于衡量模型所作出的预测离真实值(Ground Truth)之间的偏离程度。 通常,我们都会最小化目标函数,最常用的算法便是“梯度下降法”(Gradient Descent)。俗话说,任何事情必然有它的两面性,因此,并没有一种万能的损失函数能够适用于所有的机器学习任务,所以在这里我们需要知道每一种损失函数的优点和局限性,才能更好的利用它们去解决实际的问题。损失函数大致可分为两种:回归损失(针对连续型变量)和分类损失(针对离散型变量)。
有关回归损失函数与分类损失函数的详细内容,见一文看尽深度学习中的各种损失函数。图像分类用的最多的是分类损失函数中的交叉熵损失函数。图像分类可分为二分类和多分类,在pytorch中也有相对应的损失函数类,分别是和 。
公式
BCELoss()是计算目标值和预测值之间的二进制交叉熵损失函数。其公式如下:
ln=?wn?[yn?logxn+(1?yn)?log(1?xn)]
其中,wn表示权重矩阵,xn表示预测值矩阵(输入矩阵被激活函数处理后的结果),yn表示目标值矩阵。
pytorch实现
语法:Class torch.nn.BCELoss(weight: Union[torch.Tensor, NoneType]=None, size_average=None, reduce=None, reduction: str='mean')
参数:
最常用的参数为 reduction(str, optional) ,可设置其值为 mean, sum, none ,默认为 mean。该参数主要影响多个样本输入时,损失的综合方法。mean表示损失为多个样本的平均值,sum表示损失的和,none表示不综合。其他参数读者可查阅官方文档。
注意:类别是one-hot二维向量形式,不能是index形式,这是因为
,pre、tgt必须具有相同的形状。
torch.nn.CrossEntropyLoss() 参数、计算过程以及及输入Tensor形状,这篇文章介绍的足够详实,以下内容摘自此文章。
交叉熵损失函数一般用于多分类问题。现有C分类问题,(x, y)是训练集中的一个样本,其中x是样本的属性,y∈[0, 1]C为样本类别标签。将x输入模型,得到样本的类别预测值y~∈[0, 1]C,采用交叉熵损失计算类别预测值y~和真实值 y 之间的距离:
简单定义两个Tensor,其中pre为模型的预测值,tgt为类别真实标签,采用one-hot形式表示。
语法:torch.nn.CrossEntropyLoss(weight: Union[torch.Tensor, NoneType]=None, size_average=None, ignore_index: int=-100, reduce=None, reduction: str='mean', label_smoothing: float=0.0)
参数:
最常用的参数为 reduction(str, optional) ,可设置其值为 mean, sum, none ,默认为 mean。该参数主要影响多个样本输入时,损失的综合方法。mean表示损失为多个样本的平均值,sum表示损失的和,none表示不综合。其他参数读者可查阅官方文档。
我们还是使用Quick Start中的例子。
由此可见:
①交叉熵损失函数会自动对输入模型的预测值进行softmax。因此在多分类问题中,如果使用nn.CrossEntropyLoss(),则预测模型的输出层无需添加softmax层。
②nn.CrossEntropyLoss()=nn.LogSoftmax()+nn.NLLLoss()。
为了直观显示函数输出结果,我们将参数reduction设置为none。此外pre表示模型的预测值,为4*4的Tensor,其中的每行表示某个样本的类别预测(4个类别);tgt表示样本类别的真实值,有两种表示形式,一种是类别的index,另一种是one-hot形式。
pre形状为Tensor(C);两种tgt的形状分别为Tensor(), Tensor(C) 。此时①手动计算损失②损失函数+tgt_index形式③损失函数+tgt_onehot形式:
可见torch.nn.CrossEntropyLoss()接受两种形式的标签输入,一种是类别index,一种是one-hot形式。
pre形状为Tensor(N, C);两种tgt的形状分别为Tensor(N), Tensor(N, C) 。此时①手动计算损失②损失函数+tgt_index形式③损失函数+tgt_onehot形式:
优化器主要是在模型训练阶段对模型可学习参数进行更新, 所有的优化器都是继承类,常用优化器有 SGD,RMSprop,Adam等。基本用法如下:
有关更详细的内容,见PyTorch 源码解读之 torch.optim:优化算法接口详解。
以下内容摘自Pytorch优化器全总结(一)SGD、ASGD、Rprop、Adagrad_pytorch sgd优化器_小殊小殊的博客-CSDN博客系列。
SGD算法解析
明明类名是SGD,为什么介绍MBGD呢,因为在Pytorch中,torch.optim.SGD其实是实现的MBGD,要想使用SGD,只要将batch_size设成1就行了。
MBGD就是结合BGD和SGD的折中,对于含有 n个训练样本的数据集,每次参数更新,选择一个大小为 m(m<n) 的mini-batch数据样本计算其梯度,其参数更新公式如下,其中j是一个batch的开始: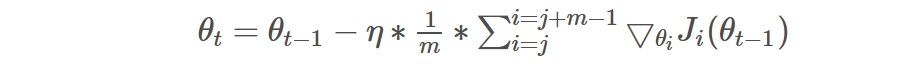
优点:使用mini-batch的时候,可以收敛得很快,有一定摆脱局部最优的能力。
缺点:a.在随机选择梯度的同时会引入噪声,使得权值更新的方向不一定正确
b.不能解决局部最优解的问题
动量是一种有助于在相关方向上加速SGD并抑制振荡的方法,通过将当前梯度与过去梯度加权平均,来获取即将更新的梯度。如下图b图所示。它通过将过去时间步长的更新向量的一小部分添加到当前更新向量来实现这一点: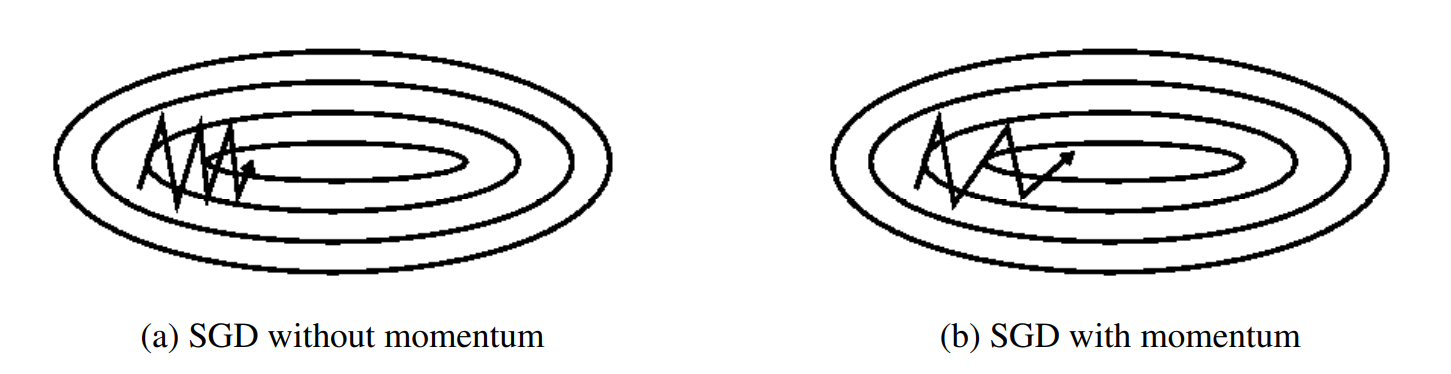
动量项通常设置为0.9或类似值。
NAG的思想是在动量法的基础上展开的。动量法是思想是,将当前梯度与过去梯度加权平均,来获取即将更新的梯度。在知道梯度之后,更新自变量到新的位置。也就是说我们其实在每一步,是知道下一时刻位置的。这时Nesterov就说了:那既然这样的话,我们何不直接采用下一时刻的梯度来和上一时刻梯度进行加权平均呢?下面两张图看明白,就理解NAG了:
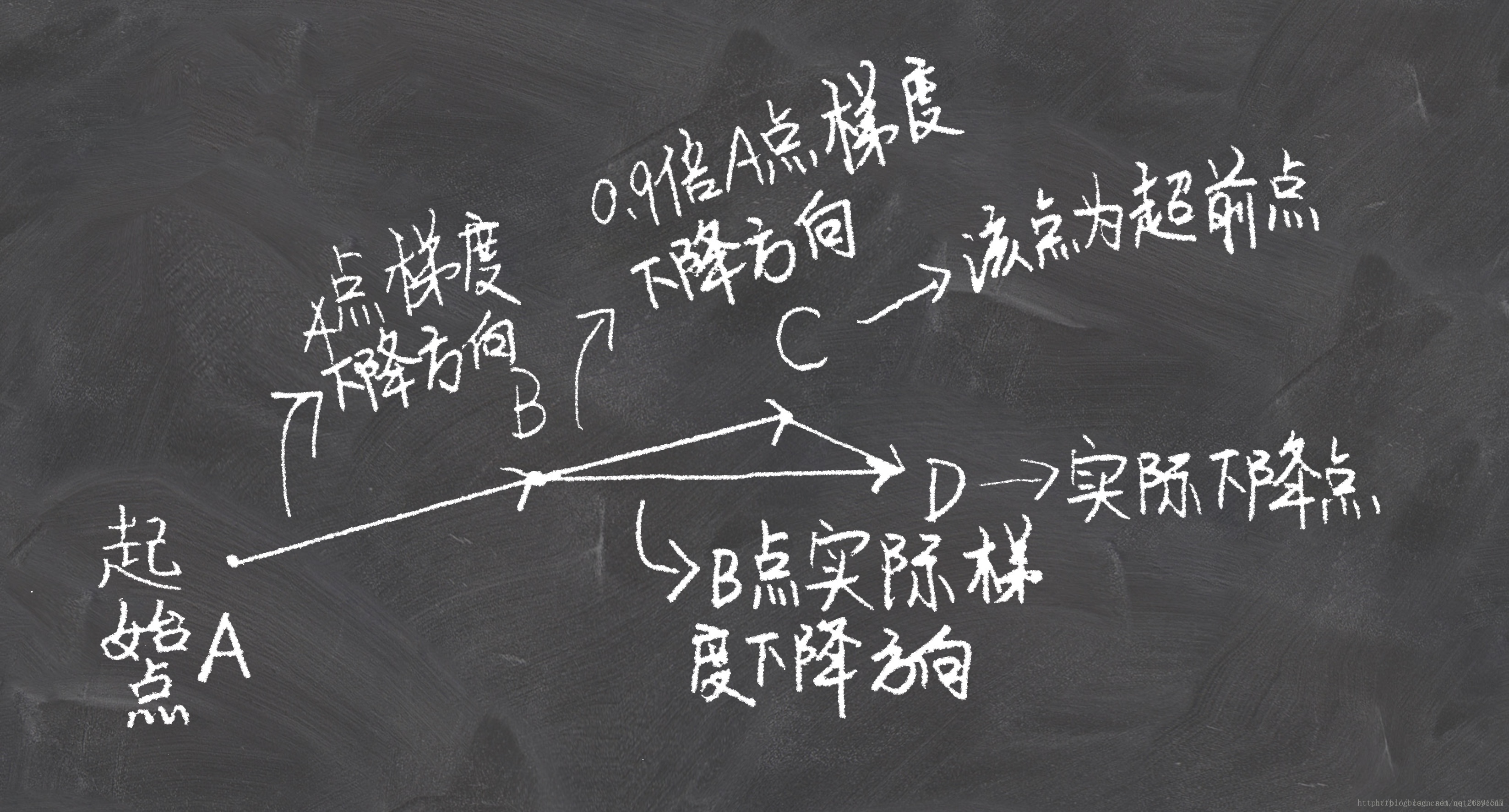
SGD总结
使用了Momentum或NAG的MBGD有如下特点:
优点:加快收敛速度,有一定摆脱局部最优的能力,一定程度上缓解了没有动量的时候的问题
缺点:a.仍然继承了一部分SGD的缺点
b.在随机梯度情况下,NAG对收敛率的作用不是很大
c.Momentum和NAG都是为了使梯度更新更灵活。但是人工设计的学习率总是有些生硬,下面介绍几种自适应学习率的方法。
推荐程度:带Momentum的torch.optim.SGD 可以一试。
RMSprop总结
RMSprop算是Adagrad的一种发展,用梯度平方的指数加权平均代替了全部梯度的平方和,相当于只实现了Adadelta的第一个修改,效果趋于RMSprop和Adadelta二者之间。
优点:适合处理非平稳目标(包括季节性和周期性)——对于RNN效果很好
缺点:RMSprop依然依赖于全局学习率
推荐程度:推荐!
Adam总结
在adam中,一阶矩来控制模型更新的方向,二阶矩控制步长(学习率)。利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
优点:
1、结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
2、更新步长和梯度大小无关,只和alpha、beta_1、beta_2有关系。并且由它们决定步长的理论上限
3、更新的步长能够被限制在大致的范围内(初始学习率)
4、能较好的处理噪音样本,能天然地实现步长退火过程(自动调整学习率)
推荐程度:非常推荐
Accuracy指的是正确率,计算方式:acc=正确样本个数 /样本总数,以上内容想必大家都知道,下面让我们看一下在pytorch中是如何计算的吧。
模型(多分类)的输出结果是经过归一化指数函数——softmax函数(二分类是sigmoid函数)变换,将多分类结果以概率形式展现出来。因此我们需要将概率形式的分类结果转换为index,再根据分类形式(例如one-hot形式)做相应操作。与可以求最大概率的index。
这里,我们假设,则:
Loss的计算与选用的损失函数息息相关,这里我们以损失函数为例。参数reduction有三个可选值,因此有三种不同计算方式。
公司名称: 天富娱乐-天富医疗器械销售公司
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

